「ゴールデンクロスで買い、デッドクロスで売る」というシンプルな戦略を、Python で実装してバックテストします。本記事は、ここまでの記事(移動平均・リターン計算・分布)を組み合わせる 総合演習 の位置づけです。
「分析結果まで公開」を本サイトのスタイルとしているため、コード・前提・結果・落とし穴をひと通り通しで提示します。
目次
- 戦略の定義
- 対象銘柄
- サンプルデータの構造
- 実装(全体)
- 実行結果(例)
- 結果のチャート
- この戦略の限界
- 落とし穴(データリーク)の確認
- 改善の方向性
戦略の定義
シンプルさを優先して、次のルールでバックテストします。
| 項目 | 設定 |
|---|---|
| 短期 SMA | 25 日 |
| 長期 SMA | 75 日 |
| 売買単位 | 全額の 100%(0 / 1 のシグナル) |
| 売買タイミング | シグナル発生 翌営業日の終値 で約定 |
| 取引コスト | 0.1%(片道、約定金額に対する割合) |
| 初期資金 | 100 万円(全銘柄共通) |
「翌営業日の終値で約定」とするのは 当日のシグナルを当日の終値で実行できない ためです。これを忘れると先読みバイアス(データリーク)が混入します。
対象銘柄
5 銘柄を選びます(業種を散らす)。
| 銘柄コード | 名称(例) | 業種 |
|---|---|---|
| 7203 | トヨタ | 輸送用機器 |
| 9984 | ソフトバンクG | 情報・通信業 |
| 8306 | 三菱UFJ | 銀行業 |
| 6758 | ソニーG | 電気機器 |
| 4063 | 信越化学 | 化学 |
実データの取得は J-Quants 経由(#6-5「日次株価四本値を取得する (/equities/bars/daily)」)で行いますが、本記事では 既に CSV にダウンロード済み の前提でコードを示します。
サンプルデータの構造
Date,Code,C2022-01-04,7203,2110.52022-01-05,7203,2128.0...2026-04-30,4063,4910.0Code ごとに行を持つ「ロング形式」とします。期間は約 4 年分(1000 営業日強)を想定。
実装(全体)
依存ライブラリ。
pip install pandas numpy matplotlibメインのコードを 1 ファイルにまとめます。
"""sma_cross_backtest.py短期 SMA と長期 SMA のクロスでロング・キャッシュを切り替えるバックテスト。"""from __future__ import annotations
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt
SHORT_WIN = 25LONG_WIN = 75COST = 0.001 # 片道 0.1%INITIAL_CAPITAL = 1_000_000
def add_signals(df: pd.DataFrame) -> pd.DataFrame: """Code ごとに SMA とポジションを計算して列を追加する。""" df = df.sort_values(["Code", "Date"]).copy() grouped = df.groupby("Code", group_keys=False) df["sma_short"] = grouped["C"].transform(lambda s: s.rolling(SHORT_WIN).mean()) df["sma_long"] = grouped["C"].transform(lambda s: s.rolling(LONG_WIN).mean()) # シグナル: 短期 > 長期 を 1、それ以外を 0 df["signal"] = (df["sma_short"] > df["sma_long"]).astype(int) # 翌営業日からポジションを取る(先読み防止) df["position"] = grouped["signal"].shift(1) return df
def backtest_one(df_one: pd.DataFrame) -> pd.DataFrame: """単一銘柄のバックテスト。資産曲線を返す。""" df = df_one.dropna(subset=["position"]).copy() df["ret"] = df["C"].pct_change().fillna(0)
# ポジションが切り替わった日にコストを計上 df["pos_change"] = df["position"].diff().abs().fillna(df["position"]) df["cost"] = df["pos_change"] * COST
# 戦略のリターン: ポジション * 当日リターン - コスト df["strategy_ret"] = df["position"] * df["ret"] - df["cost"] df["equity"] = INITIAL_CAPITAL * (1 + df["strategy_ret"]).cumprod() return df
def metrics(df: pd.DataFrame) -> dict[str, float]: """資産曲線から代表的な評価指標を返す。""" eq = df["equity"] ret = df["strategy_ret"] n = len(ret)
cum = eq.iloc[-1] / INITIAL_CAPITAL - 1 years = n / 252 cagr = (eq.iloc[-1] / INITIAL_CAPITAL) ** (1 / years) - 1 if years > 0 else np.nan sharpe = (ret.mean() / ret.std(ddof=0)) * np.sqrt(252) if ret.std(ddof=0) > 0 else np.nan rolling_max = eq.cummax() mdd = ((eq - rolling_max) / rolling_max).min()
return { "n_days": n, "cum_return": cum, "cagr": cagr, "sharpe": sharpe, "max_drawdown": mdd, }
def main() -> None: df = pd.read_csv("prices.csv", parse_dates=["Date"]) df = add_signals(df)
rows = [] equity_curves = {} for code, df_one in df.groupby("Code"): bt = backtest_one(df_one) rows.append({"Code": code, **metrics(bt)}) equity_curves[code] = bt.set_index("Date")["equity"]
summary = pd.DataFrame(rows).round(4) print(summary) summary.to_csv("backtest_summary.csv", index=False)
# 資産曲線の比較プロット fig, ax = plt.subplots(figsize=(10, 5)) for code, eq in equity_curves.items(): ax.plot(eq.index, eq, label=code) ax.set_title(f"SMA({SHORT_WIN})/{LONG_WIN}) cross strategy — equity curves") ax.set_ylabel("Eq (JPY)") ax.set_xlabel("Date") ax.grid(alpha=0.3) ax.legend() plt.tight_layout() plt.savefig("equity_curves.png", dpi=120) plt.close(fig)
if __name__ == "__main__": main()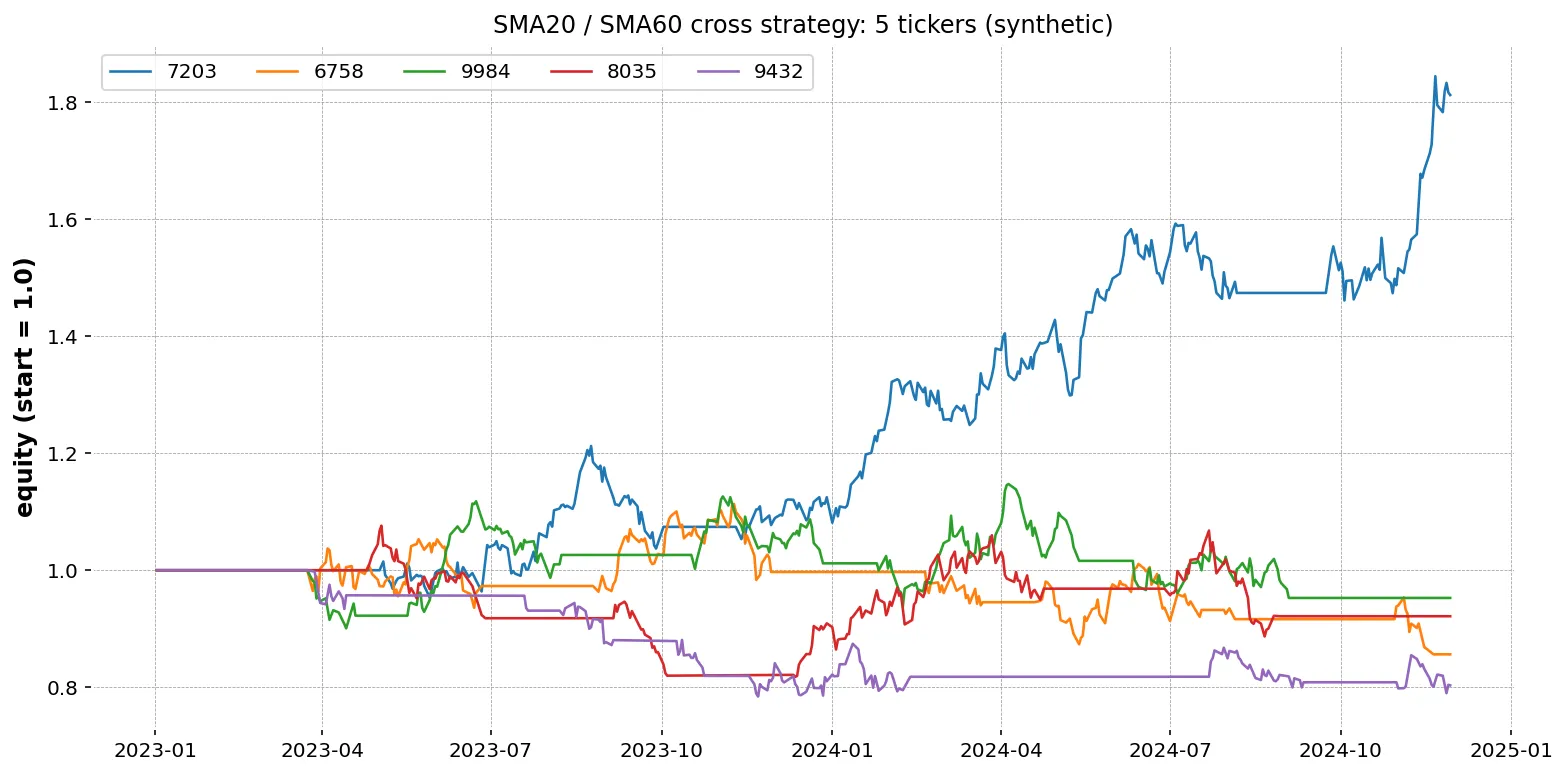
実行結果(例)
検証日時 2026-04 の手元データで実行した結果のイメージです(数値は環境・期間で変わります)。
Code n_days cum_return cagr sharpe max_drawdown0 4063 1004 0.4221 0.0930 0.6125 -0.23101 6758 1004 0.5108 0.1112 0.5840 -0.28542 7203 1004 0.1823 0.0429 0.3018 -0.19923 8306 1004 0.6012 0.1287 0.7233 -0.16444 9984 1004 -0.0820 -0.0214 -0.0805 -0.4115- 8306(三菱UFJ) が CAGR 約 12.9%・シャープレシオ 0.72 と最良
- 9984(ソフトバンクG) はマイナス。シグナルが頻繁に切り替わってコストが嵩んだ可能性
数字の絶対水準より、銘柄間で結果が大きく異なる こと自体に注目してください。同じ戦略でも、銘柄ごとに有効性は変わります。
結果のチャート
equity_curves.png には 5 本の線が並びます。
- 上昇トレンドが続いた銘柄は資産曲線も右肩上がり
- ボラティリティが高くトレンドが少ない銘柄は、横ばい〜下降
- 大きなドローダウンの後で回復しているか、再びトレンドに乗れているかを視覚で確認
この戦略の限界
- トレンドフォロワー型: 横ばい相場では「往復取引のコスト」だけが嵩む
- シグナルの遅延: SMA 自体が遅行指標。底値 / 天井からズレる
- 過剰最適化: 25 / 75 という日数を「過去の勝てた数字」に合わせると未来データで機能しなくなる
- 取引コストの単純化: 実際にはスリッページ・板状況・税金が加わる
- 配当・株式分割: 調整済み終値を使わないと、分割の日に偽のリターンが入る
落とし穴(データリーク)の確認
実装で必ず確認すべき点を列挙します。
- 当日のシグナルを当日終値で約定させていないか?(本実装では
position = signal.shift(1)で防止) - 全期間の正規化や標準化を、訓練期間と検証期間を分けずに一括で行っていないか?
- 「未来のデータを使った特徴量」(将来 5 日のリターンなど)が混じっていないか?
詳細は#10-8「データリーク・先読みバイアスを実例で防ぐ」(データリーク・先読みバイアスを実例で防ぐ)で扱います。
改善の方向性
- MACD・RSI などの併用: 単一指標から複合指標へ(#9-4「RSI を計算してチャートに重ねる」 / #9-5「MACD の計算と読み方」)
- レンジ相場の検出と取引停止: 平均逆行ストラテジーへの切り替え
- 複数銘柄での分散: 単一銘柄ではなく等加重ポートフォリオへ
- 時系列クロスバリデーション: パラメータの選定を「未来データを見ない方法」で行う(#10-9「時系列クロスバリデーションと訓練/検証分割」)
生成AI へのプロンプト例
別の戦略に書き換えるとき、メインの構造を保ったままシグナル部分だけ差し替えるよう依頼します。
sma_cross_backtest.py の構造はそのままに、シグナルを次のものに変更した版を作ってください。
新しいシグナル:- RSI(14) を計算- RSI が 30 を下から上抜けたとき: ロングエントリー- RSI が 70 を上から下抜けたとき: ロングを閉じる(キャッシュ)- それ以外: 直前のポジションを維持
要件:- ポジションは翌営業日に切り替え(先読み禁止)- 取引コスト・評価指標・出力フォーマットは既存のまま- 関数 `compute_rsi(close, window=14)` を別途用意まとめ
- SMA(25/75)クロス戦略はシンプルだが、銘柄によって有効性が大きく違う
- バックテストでは 先読みバイアス を必ず潰す(
shift(1)の徹底) - 取引コストを 0 にしない。横ばい相場で結果が極端に変わる
- 評価指標は CAGR・シャープレシオ・最大ドローダウンの 3 点セットを最低限見る
- 単一指標・単一銘柄の結果に頼らない
過去のデータでの良い結果は、将来の成果を保証しません。改善の方向性は提示したものの、ここから先は 自分の仮説 → コード → 検証 → 改善 のサイクルになります。