ここまでの実践ケース記事で扱った指標計算・スクリーニング・可視化を、1 つの「ウォッチリスト分析テンプレート」に統合します。本記事は、これまでの総まとめとして、自分のウォッチリストに対して定期的に同じ集計を回せるテンプレートを公開します。
過去の集計結果は将来の値動きや業績を保証しません。本記事はテンプレートの設計と運用方法を学ぶための教材です。
目次
- テンプレートの全体像
- 集計する指標
- 必要なライブラリ
- コード(コピペで動く)
- 出力例
- レポート Markdown の自動生成(任意)
- メモ
- 運用するうえでの工夫
- 落とし穴
テンプレートの全体像
入力と出力を先に決めます。
| 入出力 | 内容 |
|---|---|
| 入力 | watchlist.csv(Code, label) — 自分が追跡したい銘柄 |
| 入力 | prices.csv(Code, Date, C) |
| 入力 | statements.csv(Code, DiscDate, EPS, FEPS, FDivAnn, BPS) |
| 出力 | report.md(数値表 + 簡易レビュー) |
| 出力 | report_chart.png(リスク・リターン散布図) |
入力 CSV は J-Quants から取得済みの前提です。テンプレートは「集計から先」を担当します。
集計する指標
各銘柄ごとに次を出します。
- valuation: 直近終値 / PER / PBR / 配当利回り
- profit: ROE 相当(純利益 / 自己資本)、過去 4 期 EPS 平均
- risk: 直近 252 営業日の年率ボラティリティ、最大ドローダウン
- return: 直近 252 営業日の年率リターン、累積リターン
これまでのケース記事(#11-1「高配当利回りトップ 30 を AI と一緒に抽出する」 / #11-2「プライム市場の業種別 PER ランキング」 / #11-4「ボラティリティの低い銘柄を抽出して比較」 / #11-6「決算サプライズと翌日リターンの関係を見る」)で扱った計算をひとつにまとめる構造です。
必要なライブラリ
pip install pandas numpy matplotlib検証バージョン: Python 3.12.5 / pandas 2.2.3 / numpy 2.0 / matplotlib 3.9
コード(コピペで動く)
"""watchlist_template.py自分のウォッチリストに対して、価値評価・リスク・リターン指標をまとめて計算する。"""from __future__ import annotations
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt
WATCHLIST_PATH = "watchlist.csv" # Code, labelPRICES_PATH = "prices.csv"STATEMENTS_PATH = "statements.csv"WINDOW = 252
def latest_close(prices: pd.DataFrame) -> pd.DataFrame: p = prices.sort_values(["Code", "Date"]) return p.groupby("Code", as_index=False).tail(1)[["Code", "C"]]
def risk_return_metrics(prices: pd.DataFrame) -> pd.DataFrame: p = prices.sort_values(["Code", "Date"]).copy() p["log_ret"] = np.log(p["C"] / p.groupby("Code")["C"].shift(1)) p = p.dropna(subset=["log_ret"]) p = p.groupby("Code", group_keys=False).tail(WINDOW)
grouped = p.groupby("Code") daily_mean = grouped["log_ret"].mean() daily_std = grouped["log_ret"].std(ddof=1)
# 最大ドローダウン def mdd(series: pd.Series) -> float: eq = (1 + series).cumprod() return ((eq - eq.cummax()) / eq.cummax()).min()
mdd_val = grouped["log_ret"].apply(mdd)
out = pd.DataFrame({ "ret_annual": daily_mean * 252, "vol_annual": daily_std * np.sqrt(252), "max_drawdown": mdd_val, }).reset_index() return out
def fundamental_metrics(stmt: pd.DataFrame) -> pd.DataFrame: # statements の銘柄コード列は J-Quants と同じく Code s = stmt.sort_values(["Code", "DiscDate"]) latest = s.groupby("Code", as_index=False).tail(1) return latest[["Code", "FEPS", "FDivAnn", "BPS", "NP", "Eq"]]
def main() -> None: watch = pd.read_csv(WATCHLIST_PATH) prices = pd.read_csv(PRICES_PATH, parse_dates=["Date"]) stmt = pd.read_csv(STATEMENTS_PATH, parse_dates=["DiscDate"])
prices = prices[prices["Code"].isin(watch["Code"])] stmt = stmt[stmt["Code"].isin(watch["Code"])]
closes = latest_close(prices) risk = risk_return_metrics(prices) fund = fundamental_metrics(stmt)
# watch / prices は Code、statements 由来の fund は Code。結合時に対応づける df = ( watch.merge(closes, on="Code") .merge(risk, on="Code", how="left") .merge(fund, on="Code", how="left") ) df["per"] = df["C"] / df["FEPS"] df["pbr"] = df["C"] / df["BPS"] df["dividend_yield"] = df["FDivAnn"] / df["C"] df["roe"] = df["NP"] / df["Eq"]
cols = ["Code", "label", "C", "per", "pbr", "dividend_yield", "roe", "ret_annual", "vol_annual", "max_drawdown"] df = df[cols].round(4) df.to_csv("watchlist_metrics.csv", index=False) print(df)
# リスク・リターン散布図 fig, ax = plt.subplots(figsize=(7, 5)) ax.scatter(df["vol_annual"] * 100, df["ret_annual"] * 100, s=40) for _, row in df.iterrows(): ax.annotate(row["label"], (row["vol_annual"] * 100, row["ret_annual"] * 100), fontsize=8, xytext=(4, 4), textcoords="offset points") ax.set_xlabel("Volatility (annualized, %)") ax.set_ylabel("Return (annualized, %)") ax.set_title("Watchlist — risk vs return") ax.axhline(0, color="gray", linewidth=0.8) ax.grid(alpha=0.3) plt.tight_layout() plt.savefig("report_chart.png", dpi=120) plt.close(fig)
if __name__ == "__main__": main()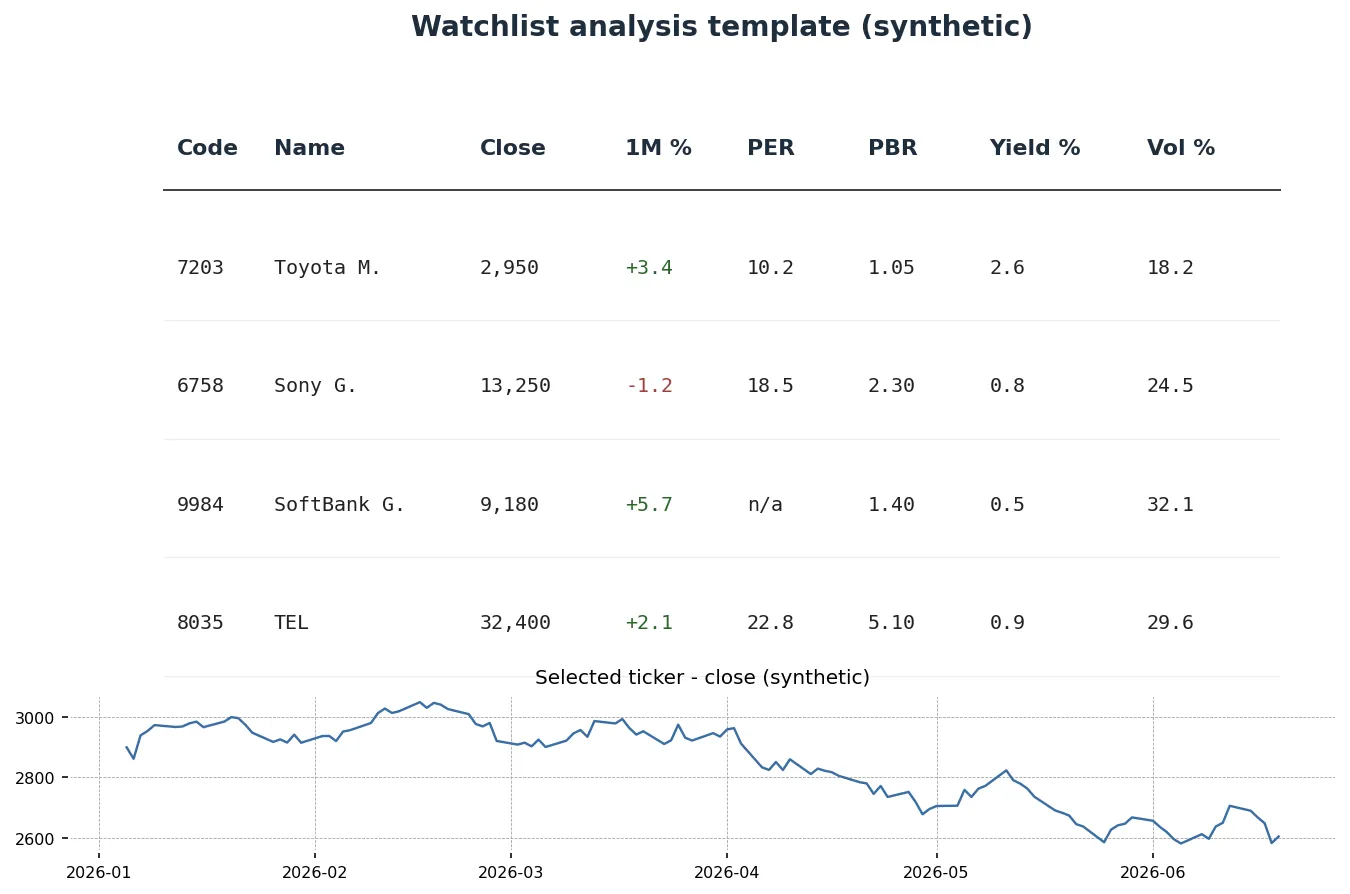
出力例
Code label C per pbr dividend_yield roe ret_annual vol_annual max_drawdown0 XXXX AAA 2925.0 16.20 1.42 0.0240 0.085 0.0820 0.2210 -0.18201 XXXX BBB 1820.0 9.85 0.92 0.0410 0.094 -0.0125 0.2540 -0.25102 XXXX CCC 4210.0 22.45 3.10 0.0145 0.142 0.1310 0.2620 -0.21503 XXXX DDD 3875.0 18.30 2.05 0.0205 0.115 0.0625 0.2050 -0.16904 XXXX EEE 1245.0 11.10 1.20 0.0382 0.108 0.0915 0.1880 -0.1450report_chart.png にはウォッチリストの 5 銘柄が、年率ボラティリティと年率リターンの散布図上にラベル付きで並びます。自分の追跡対象だけ のシンプルな図になるため、傾向を直感的に把握しやすくなります。
レポート Markdown の自動生成(任意)
数値表を Markdown に変換し、定期レポートのテンプレートに差し込みます。
def to_markdown_report(df: pd.DataFrame) -> str: rows = df.to_markdown(index=False) return f"""# Watchlist report
{rows}
## メモ- 集計期間: 直近 {WINDOW} 営業日- PER・PBR・配当利回りは予想値ベース、ROE は当期実績ベース"""
with open("report.md", "w", encoding="utf-8") as f: f.write(to_markdown_report(df))文章化を生成AI に任せる場合は、この report.md をそのまま#11-5「同業他社比較レポートを生成AIに作らせる」 のプロンプトに渡せます。
運用するうえでの工夫
定期実行に耐える形に育てる過程で効くのは、ファイル管理の規律です。
- 日付付きの出力ディレクトリ(例:
reports/2026-05-11/)に CSV と PNG を保存 - 集計コード本体は変更せず、ウォッチリスト CSV だけを差し替える
- 設定値(
WINDOWなど)は冒頭の定数に集約 - 集計の結果が大きく変わったら、入力データの欠損・更新タイミングをまず確認
落とし穴
- 指標の組み合わせの罠: PER 低・配当利回り高・ROE 高、すべて満たす銘柄は少ない。条件を AND でつなぐと 0 件になりやすい
- 欠損の扱い: PBR や ROE が NaN の銘柄を散布図から落とすかどうかを決めておく
- 更新タイミング: 株価は毎日、財務は四半期。同じ集計でも財務が更新されない週は変動が小さく見える
- 個別の納得感: 数字だけで判断せず、自分が持っている定性情報と突き合わせる
まとめ
- 1 ファイルのテンプレートに、価値評価・リスク・リターンの指標をまとめて計算
- 入力はウォッチリスト CSV と J-Quants から取得済みの 2 ファイルだけ
- 出力は CSV、散布図 PNG、Markdown レポートの 3 種類
- 定期運用は出力ディレクトリの命名規則と設定の集約で支える
- 集計は手段。最終的な判断は自分の定性情報も含めて行う
過去の集計は将来の業績・株価を保証しません。