定量分析の結果は「チャートで触れる」状態になると、数字だけ眺めるよりも理解が深まります。本記事はリターン分布のヒストグラム、相関行列のヒートマップ、ドローダウンの面チャートを Plotly で作る実例集です。
目次
- サンプルデータ
-
- リターン分布のヒストグラム
-
- 相関行列のヒートマップ
-
- ドローダウンの面チャート
-
- リスク・リターン散布図(ホバー付き)
- 落とし穴
サンプルデータ
5 銘柄の日次終値を持つ CSV を想定します。
Date,Code,C2025-01-06,7203,28402025-01-06,9984,8210...ロング形式から、リターンと相関の計算用にワイド形式に変換します。
import pandas as pd
prices = pd.read_csv("prices.csv", parse_dates=["Date"])wide = prices.pivot(index="Date", columns="Code", values="C").sort_index()returns = wide.pct_change().dropna()検証バージョン: Python 3.12.5 / pandas 2.2.3 / numpy 2.0 / plotly 5.20
1. リターン分布のヒストグラム
リターンの形(分布の歪み・裾の厚み)を見るには重ね合わせヒストグラムが向きます。
import plotly.graph_objects as go
fig = go.Figure()for code in returns.columns: fig.add_trace(go.Histogram( x=returns[code] * 100, name=str(code), opacity=0.55, nbinsx=60, ))fig.update_layout( barmode="overlay", # 重ねる title="Daily return distribution (%)", xaxis_title="Daily return (%)", yaxis_title="Frequency", template="plotly_white",)fig.write_html("returns_hist.html")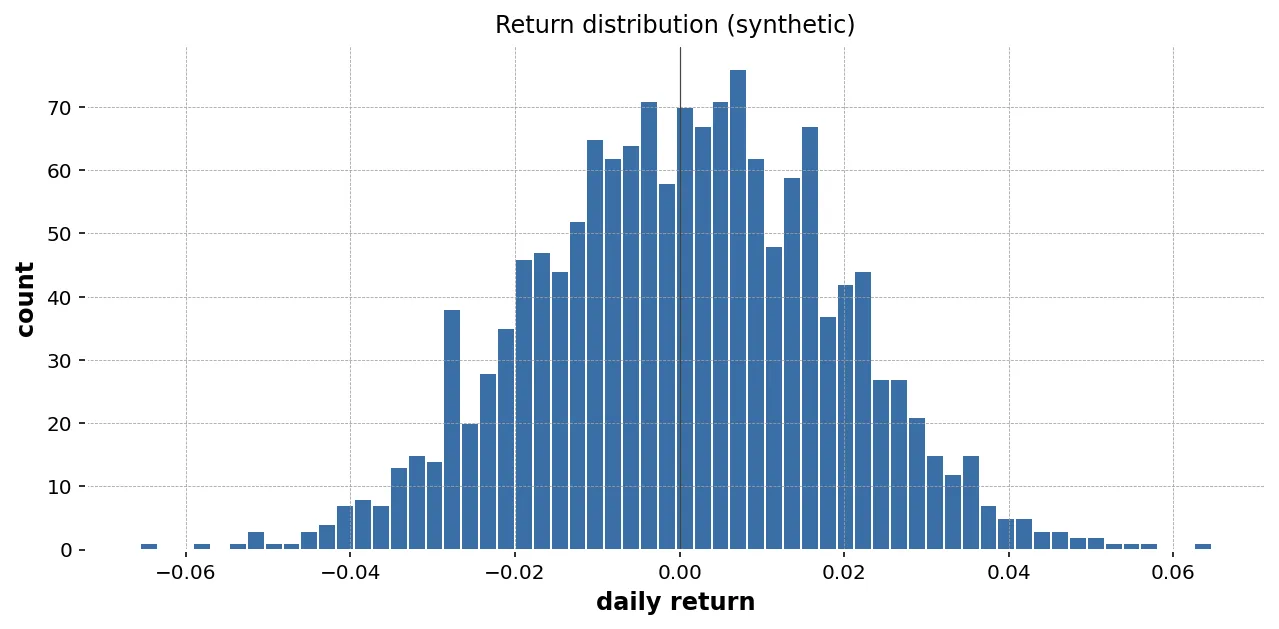
barmode="overlay"で重ねるopacity=0.55で奥側のバーも見えるnbinsxはサンプル数に応じて 30 〜 80 程度
平均がほぼ 0 で対称、しかし裾が厚い、というリターンの典型的な形が観察しやすくなります。
2. 相関行列のヒートマップ
複数銘柄の相関を見るときはヒートマップが定番です。
import plotly.graph_objects as go
corr = returns.corr().round(3)
fig = go.Figure(go.Heatmap( z=corr.values, x=corr.columns.astype(str), y=corr.index.astype(str), zmin=-1, zmax=1, colorscale="RdBu", reversescale=True, colorbar=dict(title="ρ"), text=corr.values, texttemplate="%{text:.2f}", hovertemplate="x=%{x}<br>y=%{y}<br>corr=%{z:.3f}<extra></extra>",))fig.update_layout( title="Correlation matrix — daily returns", template="plotly_white",)fig.write_html("corr_heatmap.html")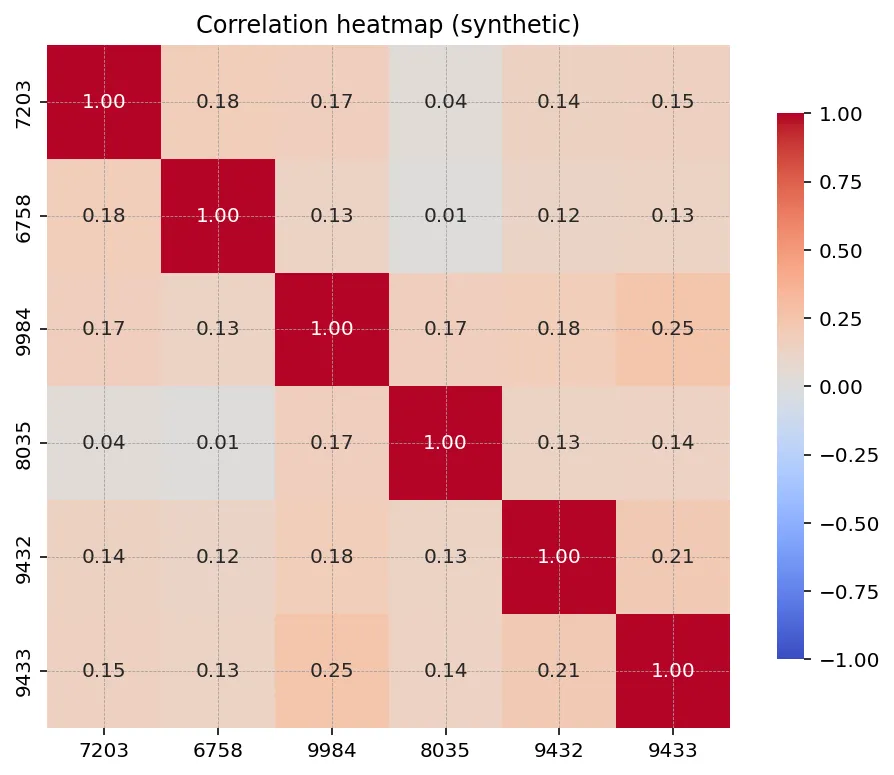
zmin=-1, zmax=1を必ず固定する。これを忘れるとデータごとに色が変わって比較できないRdBuの色は中央が 0、両端が ±1。視認性が高いtexttemplateでセル内に数値を直接書ける
セル内に数値を表示するため、何銘柄並べても色だけで判断せずに済みます。
3. ドローダウンの面チャート
ドローダウンは「直近のピークからの下落率」を時系列で見る指標です。リターンの累積から計算できます。
import plotly.graph_objects as go
equity = (1 + returns).cumprod()peak = equity.cummax()drawdown = (equity / peak - 1) * 100 # %
fig = go.Figure()for code in drawdown.columns: fig.add_trace(go.Scatter( x=drawdown.index, y=drawdown[code], name=str(code), mode="lines", fill="tozeroy", # 0 ラインまで塗る opacity=0.4, ))fig.update_layout( title="Drawdown — daily, %", yaxis_title="Drawdown (%)", template="plotly_white", hovermode="x unified",)fig.write_html("drawdown.html")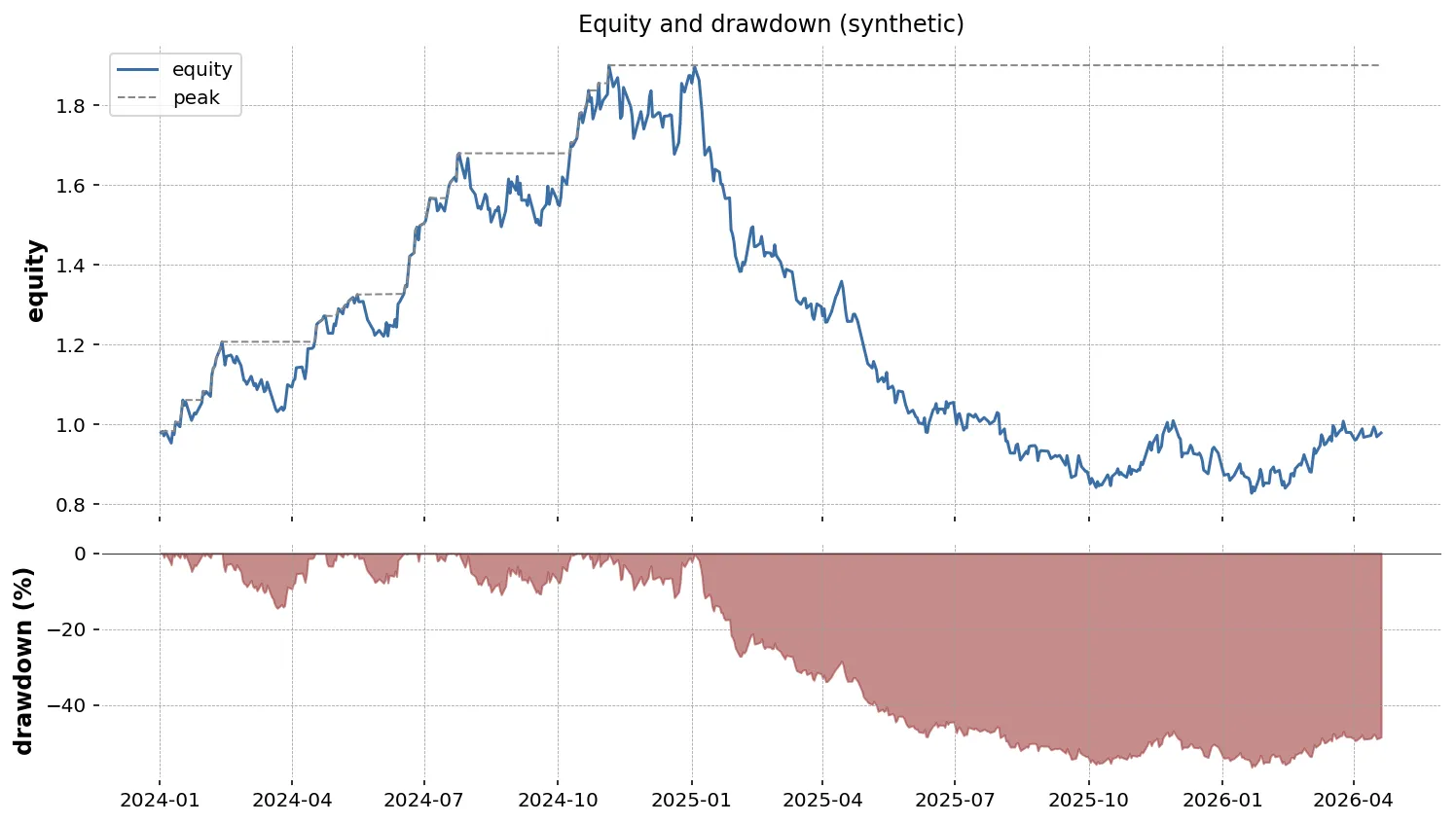
fill="tozeroy"で 0 ラインまで塗ると深さの感覚が掴みやすいhovermode="x unified"で同じ日付の全銘柄を一括表示- 単位は %(0.1 ではなく 10 と表示)が読みやすい
最大ドローダウンは数値で 1 度確認したうえで、面チャートで「どの局面で下げたか」を視覚的に確かめる、という二段構えが定番です。
4. リスク・リターン散布図(ホバー付き)
実践ケース記事で使ったような散布図も、Plotly ならホバーで銘柄名を出せます。
import numpy as npimport plotly.graph_objects as go
stats = pd.DataFrame({ "ret_annual": returns.mean() * 252, "vol_annual": returns.std(ddof=1) * np.sqrt(252),})stats = stats.reset_index().rename(columns={"Code": "Code"})
fig = go.Figure(go.Scatter( x=stats["vol_annual"] * 100, y=stats["ret_annual"] * 100, mode="markers+text", text=stats["Code"].astype(str), textposition="top center", marker=dict(size=10), hovertemplate="code=%{text}<br>vol=%{x:.2f}%<br>ret=%{y:.2f}%<extra></extra>",))fig.update_layout( title="Annualized risk vs return", xaxis_title="Volatility (%)", yaxis_title="Return (%)", template="plotly_white",)fig.write_html("risk_return.html")リスト中の銘柄名を点の上に直接書きつつ、ホバーで詳細値を出します。情報量と読みやすさのバランスが取れます。
落とし穴
- 対数 vs 単純リターン: ヒストグラムでは対数リターンの方が対称に見えやすい
- 計算窓のサイズ: 60 日 / 252 日 / 504 日で結果は大きく変わる。複数の窓で並行して見る
- 欠損データ:
pivot直後のwideには NaN が混じる。dropna()をどこで打つかで結果が変わる - 相関の安定性: 短期間ではノイズで相関が変動する。期間を分けて 2 度計算して比較する
- ヒストグラムのビン: ビン数を変えると形が変わる。固定したい場合は
xbins=dict(start=..., end=..., size=...)を指定
生成AI へのプロンプト例
目的:複数銘柄の日次リターン DataFrame を入力に、Plotly で次の 3 種類の図を作る関数を書く。
入力:returns(行: 日付, 列: 銘柄コード, 値: 単純リターン)
要件:- plot_returns_hist(returns) → 重ね合わせヒストグラム(opacity 0.55)- plot_corr(returns) → ヒートマップ(zmin=-1, zmax=1, RdBu)- plot_drawdown(returns) → 0 ラインまで塗りつぶした面チャート
制約:- plotly 5.20 系- 各関数は go.Figure を返す- write_html はメイン側で行う- xaxis/yaxis の単位は % で表示まとめ
- 分布はヒストグラム、関係はヒートマップ、変化は面チャートで見せる
- 色のレンジ(
zmin/zmax)は手で固定する。データ依存にしない - ホバー設定(
hovertemplate、hovermode="x unified")で「触って探る」体験になる - ファイルは HTML 出力にして、ノートブックや Streamlit に流用する