バックテスト結果を Notebook に閉じておくと、別の人や別の日の自分が再現するのに手間がかかります。本記事は、#11-3「移動平均クロス戦略を 5 銘柄でバックテスト」 で作った SMA クロス戦略の結果を Streamlit でダッシュボード化し、URL クエリパラメータで設定を渡せる形にまとめる手順を公開します。
本記事は結果共有の枠組みを学ぶための教材です。
目次
- 完成イメージ
- 入力データ
- アプリ本体
- URL クエリパラメータで渡す
- キャッシュとデータ更新
- レイアウトの工夫
- 落とし穴
完成イメージ
| パーツ | 役割 |
|---|---|
| サイドバー | 短期 SMA / 長期 SMA / コスト率 / 銘柄選択 |
| メイン上部 | CAGR・シャープレシオ・最大ドローダウン |
| メイン中段 | 資産曲線(銘柄ごと) |
| メイン下段 | 評価指標テーブル + CSV ダウンロード |
| URL | ?short=25&long=75&codes=7203,9984 |
URL を相手に渡すと、相手の画面でも同じ条件で結果が再現できます。
入力データ
事前に J-Quants から取得した日次株価を使います。
prices.csvDate,Code,C2022-01-04,7203,2110.52022-01-05,7203,2128.0...検証バージョン: Python 3.12.5 / pandas 2.2.3 / numpy 2.0 / streamlit 1.40 / plotly 5.20
アプリ本体
"""backtest_app.py — SMA クロス戦略のバックテスト結果共有ダッシュボード"""from __future__ import annotations
import numpy as npimport pandas as pdimport streamlit as stimport plotly.graph_objects as go
PRICES_PATH = "prices.csv"INITIAL_CAPITAL = 1_000_000
# --- データ・ロジック ---------------------------------------------------------
@st.cache_datadef load_prices(path: str) -> pd.DataFrame: df = pd.read_csv(path, parse_dates=["Date"]) return df.sort_values(["Code", "Date"]).reset_index(drop=True)
def add_signals(df: pd.DataFrame, short: int, long: int) -> pd.DataFrame: df = df.sort_values(["Code", "Date"]).copy() g = df.groupby("Code", group_keys=False) df["sma_s"] = g["C"].transform(lambda s: s.rolling(short).mean()) df["sma_l"] = g["C"].transform(lambda s: s.rolling(long).mean()) df["signal"] = (df["sma_s"] > df["sma_l"]).astype(int) df["position"] = g["signal"].shift(1) # 翌営業日から建てる return df
def backtest_one(df_one: pd.DataFrame, cost: float) -> pd.DataFrame: df = df_one.dropna(subset=["position"]).copy() df["ret"] = df["C"].pct_change().fillna(0) df["pos_change"] = df["position"].diff().abs().fillna(df["position"]) df["strategy_ret"] = df["position"] * df["ret"] - df["pos_change"] * cost df["equity"] = INITIAL_CAPITAL * (1 + df["strategy_ret"]).cumprod() return df
def metrics(df: pd.DataFrame) -> dict[str, float]: eq = df["equity"] ret = df["strategy_ret"] n = len(ret) years = n / 252 if n > 0 else 0 cagr = (eq.iloc[-1] / INITIAL_CAPITAL) ** (1 / years) - 1 if years > 0 else np.nan sharpe = (ret.mean() / ret.std(ddof=0)) * np.sqrt(252) if ret.std(ddof=0) > 0 else np.nan rolling_max = eq.cummax() mdd = ((eq - rolling_max) / rolling_max).min() return {"cum_return": eq.iloc[-1] / INITIAL_CAPITAL - 1, "cagr": cagr, "sharpe": sharpe, "max_drawdown": mdd}
# --- URL クエリパラメータ ---------------------------------------------------
def get_query_params() -> dict[str, str | list[str]]: qp = st.query_params # st.query_params は文字列または文字列リスト。1 件目に揃える return {k: (v if isinstance(v, str) else v[0]) for k, v in qp.items()}
def codes_from_query(default: list[str]) -> list[str]: raw = st.query_params.get("codes") if not raw: return default if isinstance(raw, list): raw = raw[0] return [c.strip() for c in raw.split(",") if c.strip()]
# --- アプリ -----------------------------------------------------------------
st.set_page_config(page_title="バックテスト結果", layout="wide")st.title("SMA クロス戦略 — バックテスト結果")
prices = load_prices(PRICES_PATH)all_codes = sorted(prices["Code"].astype(str).unique())
q = get_query_params()default_short = int(q.get("short", 25))default_long = int(q.get("long", 75))default_cost = float(q.get("cost", 0.001))default_codes = codes_from_query(default=all_codes[:5])
with st.sidebar: st.header("設定") short = st.number_input("短期 SMA(日)", 5, 100, value=default_short, step=5) long = st.number_input("長期 SMA(日)", 20, 250, value=default_long, step=5) cost = st.number_input("片道コスト", 0.0, 0.01, value=default_cost, step=0.0005, format="%.4f") codes = st.multiselect("対象銘柄", options=all_codes, default=default_codes)
# URL に現在の条件を反映(共有用)st.query_params.update(short=str(short), long=str(long), cost=str(cost), codes=",".join(codes))
if not codes or short >= long: st.warning("銘柄を選び、短期 SMA は長期 SMA より小さくしてください。") st.stop()
target = prices[prices["Code"].astype(str).isin(codes)]target = add_signals(target, short, long)
rows = []curves: dict[str, pd.Series] = {}for code, df_one in target.groupby("Code"): bt = backtest_one(df_one, cost) rows.append({"Code": str(code), **metrics(bt)}) curves[str(code)] = bt.set_index("Date")["equity"]
summary = pd.DataFrame(rows).set_index("Code")
col1, col2, col3 = st.columns(3)col1.metric("CAGR 平均", f"{summary['cagr'].mean()*100:.2f}%")col2.metric("Sharpe 平均", f"{summary['sharpe'].mean():.2f}")col3.metric("MDD 中央値", f"{summary['max_drawdown'].median()*100:.2f}%")
# 資産曲線fig = go.Figure()for code, eq in curves.items(): fig.add_trace(go.Scatter(x=eq.index, y=eq.values, name=code, mode="lines"))fig.update_layout( title=f"Eq curves — SMA({short}/{long}), cost {cost*100:.2f}%", yaxis_title="Eq (JPY)", template="plotly_white", hovermode="x unified", height=500,)st.plotly_chart(fig, use_container_width=True)
st.subheader("評価指標")st.dataframe(summary.round(4), use_container_width=True)
csv_bytes = summary.reset_index().to_csv(index=False).encode("utf-8-sig")st.download_button("評価指標 CSV", data=csv_bytes, file_name="backtest_summary.csv", mime="text/csv")
st.caption("本記事は学習用の教材です。")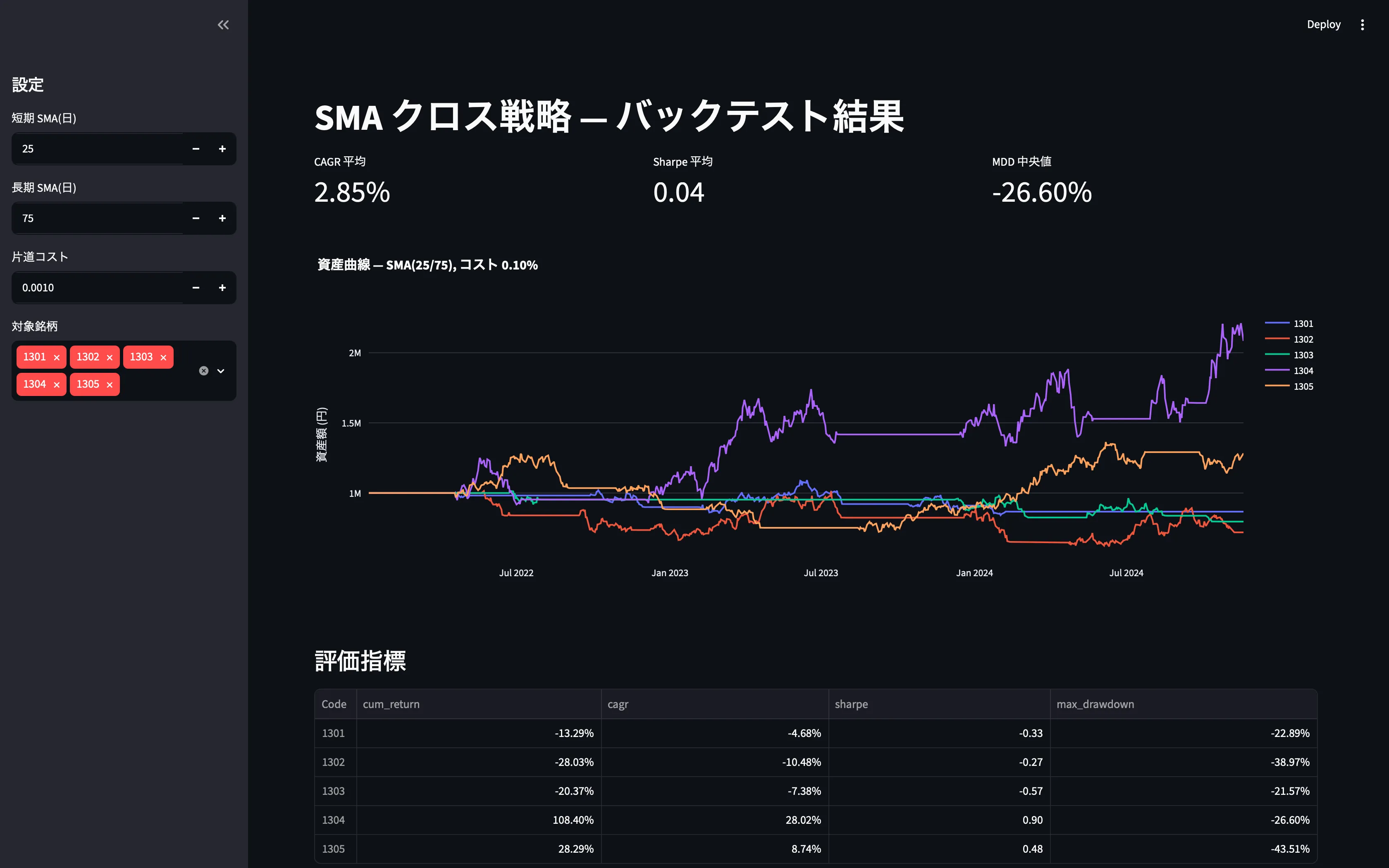
URL クエリパラメータで渡す
ダッシュボードを共有するときに、相手にも同じ条件で見てほしい場合があります。Streamlit 1.30 以降は st.query_params でクエリパラメータを読み書きできます。
http://localhost:8501/?short=20&long=60&cost=0.002&codes=7203,9984,8306このアプリは、サイドバーで値を変えるたびに st.query_params.update(...) で URL にも反映します。ブラウザの戻る・進むも自然に動き、URL コピーで設定を共有できます。
キャッシュとデータ更新
| 関数 | キャッシュの判断 |
|---|---|
load_prices | @st.cache_data を付ける(ファイルパスでキャッシュキー化) |
add_signals | 軽いのでキャッシュなしで OK |
backtest_one | 軽量だが頻繁に呼ぶならキャッシュ可 |
データを更新したら、Streamlit のメニューから「Clear cache」を実行するか、st.cache_data.clear() をコード上から呼びます。
レイアウトの工夫
- メイン上部: 重要メトリクスは 3 〜 4 個まで(
st.metricをst.columnsで並べる) - メイン中段: チャートは 1 つ。複数並べたいなら
st.tabs - メイン下段: 詳細テーブルとダウンロード
- フッター: 注意書き(
st.caption)で必ず免責を 1 行
ダッシュボードは「画面を開いてから何秒で要点が掴めるか」を最優先にします。情報を縦に積み過ぎないことが効きます。
落とし穴
- クエリパラメータの型: すべて文字列で来る。
int(...)、float(...)で変換する - multiselect の URL 反映:
,区切りで持つのが扱いやすい st.stopの場所: ガード(銘柄未選択など)を上に置き、計算前に止める- ファイルパス絶対化: デプロイ環境ではカレントディレクトリが変わる。
Path(__file__).parent / "prices.csv"のように相対パスを基準化 - 時系列の連結: 銘柄ごとに営業日数が違うと、複数曲線の長さが揃わない。共通期間に切るか、長い方をそのまま見せるかを決めておく
生成AI へのプロンプト例
目的:SMA クロス戦略(短期 SMA が長期 SMA を上抜けた翌営業日から買い建て、下抜けた翌営業日に手仕舞い)のバックテスト結果を Streamlit でダッシュボード化する。
入力:prices.csv (Date, Code, C)
UI 要件:- サイドバー: 短期 SMA / 長期 SMA / 片道コスト / 銘柄(multiselect)- メイン: CAGR 平均 / Sharpe 平均 / MDD 中央値 のメトリクス- 銘柄ごとの資産曲線を Plotly で重ね描き- 評価指標テーブルと CSV ダウンロード- URL クエリパラメータ ?short=&long=&cost=&codes= で設定を共有可
制約:- streamlit 1.40 系 / pandas 2.2 / numpy 2.0 / plotly 5.20- 翌営業日からポジションを取る(先読み禁止、shift(1))- 0 件・条件不正のときは st.warning → st.stopまとめ
- バックテストはダッシュボード化すると共有・再現が一気に楽になる
- URL クエリパラメータで設定を渡せる形にすると、相手の画面でも同じ条件を再現できる
- メトリクス → チャート → テーブル → ダウンロードの順で縦に並べる
- 重い処理は
@st.cache_data、軽い処理は素のままで十分