ファンダメンタルズ指標をスライダーで動かしながらリアルタイムに銘柄を絞り込めるツールを Streamlit で作ります。本記事はカテゴリ 8(ファンダメンタルズ)とカテゴリ 11(実践ケース)で扱った指標を、対話的に操作できる形にまとめる手順を公開します。
過去のデータでの集計は将来の業績や株価を保証しません。本記事はスクリーニング UI の組み方を学ぶための教材です。
目次
- 完成イメージ
- 入力データ
- 必要なライブラリ
- アプリ本体
- ウィジェットの設計
- 散布図の「全体 + 該当」表示
- ダウンロードボタン
- 落とし穴
完成イメージ
| パーツ | 役割 |
|---|---|
| サイドバー | PER 上限、PBR 上限、配当利回り下限、ROE 下限、市場区分、業種 |
| メイン上部 | フィルタ後の件数と平均値 |
| メイン中段 | リスク・リターン散布図(該当銘柄を強調) |
| メイン下段 | 結果テーブル(ソート・CSV ダウンロード可) |
入力データ
集計済みの 1 ファイルを前提にします。
metrics.csvCode,CoName,S33Nm,MktNm,C,per,pbr,dividend_yield,roe,ret_annual,vol_annualper、pbr は倍率、dividend_yield、roe、ret_annual、vol_annual は小数(0.04 = 4%)です。
必要なライブラリ
pip install streamlit pandas plotly検証バージョン: Python 3.12.5 / pandas 2.2.3 / streamlit 1.40 / plotly 5.20
アプリ本体
"""screener.py — ファンダメンタルズ指標で銘柄を絞り込む Streamlit アプリ"""from __future__ import annotations
import pandas as pdimport streamlit as stimport plotly.express as px
METRICS_PATH = "metrics.csv"
@st.cache_datadef load_metrics(path: str) -> pd.DataFrame: df = pd.read_csv(path) return df
def apply_filters(df: pd.DataFrame, *, per_max: float, pbr_max: float, dy_min: float, roe_min: float, markets: list[str], sectors: list[str]) -> pd.DataFrame: """サイドバーのフィルタを順に適用する。""" out = df.copy() if markets: out = out[out["MktNm"].isin(markets)] if sectors: out = out[out["S33Nm"].isin(sectors)] # PER/PBR は赤字や極端値を除外。NaN は通さない out = out[out["per"].between(0, per_max, inclusive="neither")] out = out[out["pbr"].between(0, pbr_max, inclusive="neither")] out = out[out["dividend_yield"] >= dy_min] out = out[out["roe"] >= roe_min] return out.reset_index(drop=True)
# --- アプリ -----------------------------------------------------------------
st.set_page_config(page_title="銘柄スクリーニング", layout="wide")st.title("銘柄スクリーニング")
df_all = load_metrics(METRICS_PATH)
with st.sidebar: st.header("条件") per_max = st.slider("PER 上限", 5.0, 50.0, 20.0, step=1.0) pbr_max = st.slider("PBR 上限", 0.5, 5.0, 2.0, step=0.1) dy_min = st.slider("配当利回り 下限(%)", 0.0, 8.0, 2.0, step=0.5) / 100 roe_min = st.slider("ROE 下限(%)", 0.0, 30.0, 8.0, step=1.0) / 100 markets = st.multiselect("市場区分", sorted(df_all["MktNm"].dropna().unique())) sectors = st.multiselect("業種", sorted(df_all["S33Nm"].dropna().unique()))
result = apply_filters( df_all, per_max=per_max, pbr_max=pbr_max, dy_min=dy_min, roe_min=roe_min, markets=markets, sectors=sectors,)
col1, col2, col3 = st.columns(3)col1.metric("該当銘柄数", f"{len(result):,d}")col2.metric("PER 平均", f"{result['per'].mean():.2f}" if len(result) else "—")col3.metric("配当利回り 平均", f"{result['dividend_yield'].mean()*100:.2f}%" if len(result) else "—")
if result.empty: st.warning("条件に合う銘柄はありません。フィルタを緩めてください。") st.stop()
# リスク・リターン散布図(全体グレー + 該当をハイライト)df_all_plot = df_all.assign(highlight="その他")df_all_plot.loc[df_all_plot["Code"].isin(result["Code"]), "highlight"] = "該当"fig = px.scatter( df_all_plot, x="vol_annual", y="ret_annual", color="highlight", color_discrete_map={"その他": "lightgray", "該当": "crimson"}, hover_data=["Code", "CoName", "S33Nm", "per", "pbr"], opacity=0.7, labels={"vol_annual": "Volatility", "ret_annual": "Return"},)fig.update_layout(template="plotly_white", height=500)fig.update_xaxes(tickformat=".0%")fig.update_yaxes(tickformat=".0%")st.plotly_chart(fig, use_container_width=True)
st.subheader("結果テーブル")display_cols = ["Code", "CoName", "S33Nm", "MktNm", "C", "per", "pbr", "dividend_yield", "roe", "ret_annual", "vol_annual"]st.dataframe( result[display_cols].sort_values("per").reset_index(drop=True), use_container_width=True,)
# ダウンロードボタンcsv_bytes = result[display_cols].to_csv(index=False).encode("utf-8-sig")st.download_button( label="結果を CSV でダウンロード", data=csv_bytes, file_name="screening_result.csv", mime="text/csv",)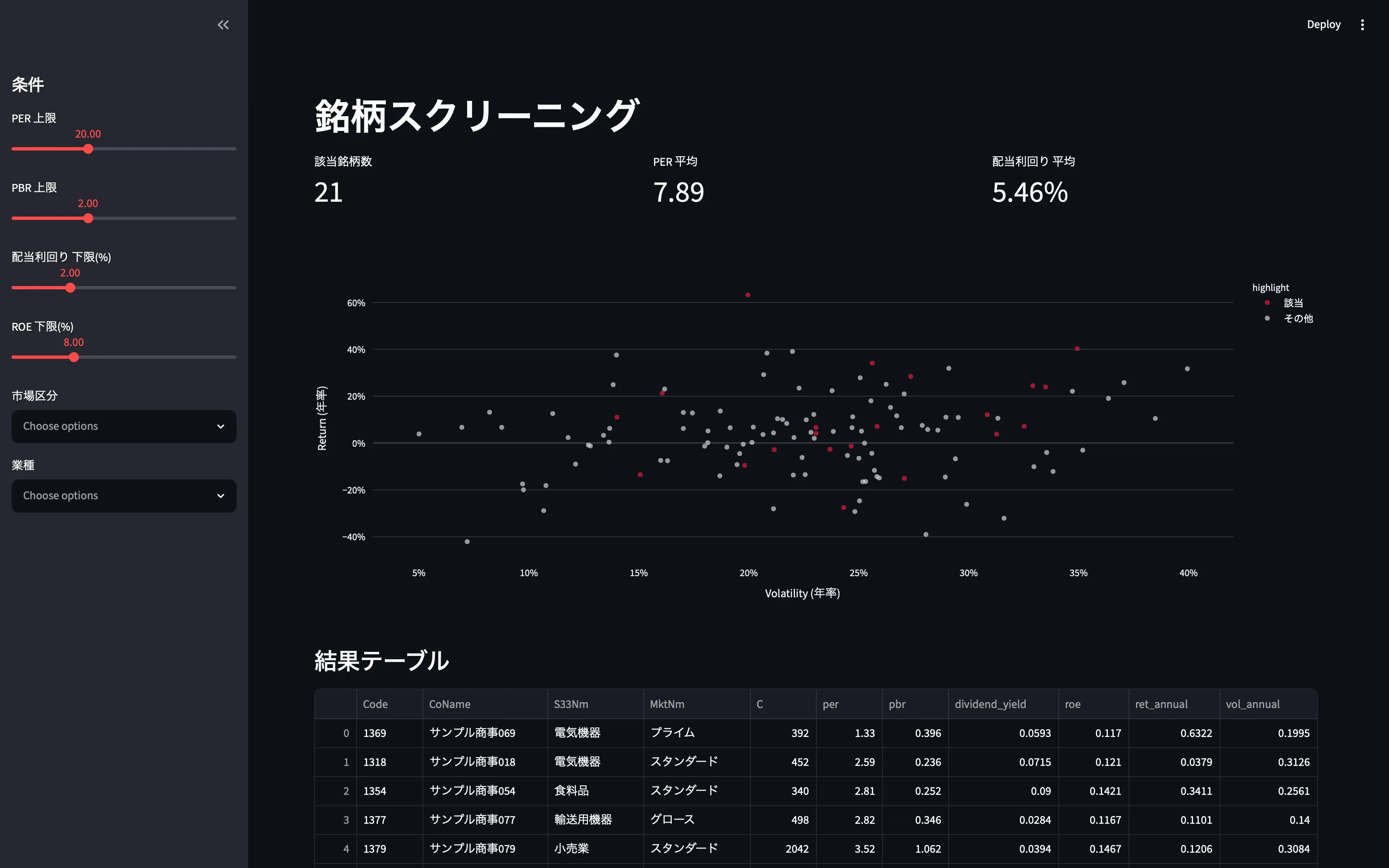
ウィジェットの設計
ウィジェット選びはユーザーの操作回数を最小化することを意識します。
| 入力の性質 | ウィジェット |
|---|---|
| 連続値の上限・下限 | slider |
| 列挙(複数選択あり) | multiselect |
| 列挙(単一選択) | selectbox |
| 真偽 | checkbox / toggle |
| 自由入力 | text_input |
スライダーの初期値 がアプリの第一印象を作ります。条件を緩めにしておくと、開いた瞬間に件数が出て操作する気になりやすくなります。
散布図の「全体 + 該当」表示
スクリーニングの本質は「全体の中で該当はどこか」です。
- 全銘柄: 薄いグレー
- 該当: 強い色(クリムゾンなど)
これだけで「条件を厳しくすると該当が散布図のどの方向にシフトするか」が直感的に追えます。
ダウンロードボタン
st.download_button で結果 CSV を 1 クリックでダウンロードできます。utf-8-sig を使うと Excel で文字化けしません。
落とし穴
- NaN の扱い:
betweenは NaN を False で返す。dropna()を冒頭で打つかどうかを意識する - 複数フィルタの AND: 条件が増えるほど該当 0 件になりやすい。1 件ずつ追加して件数を確認 が基本
- 再描画コスト: スライダーを動かすと毎回スクリプトが再実行される。重いデータは
@st.cache_dataで必ず包む - 指標の定義: PER は予想 / 実績、ROE は連結 / 単体など、データソース側の定義を必ず固定する
- 表示単位: スライダー側を %、データ側を小数で持つ場合、変換し忘れに注意
生成AI へのプロンプト例
目的:集計済みの metrics.csv を入力に、Streamlit の銘柄スクリーニングツールを作る。
入力:metrics.csv の列: Code, CoName, S33Nm, MktNm, C,per, pbr, dividend_yield, roe, ret_annual, vol_annual
UI 要件:- サイドバー - PER 上限(slider 5〜50) - PBR 上限(slider 0.5〜5) - 配当利回り 下限(slider 0〜8%、% 表示) - ROE 下限(slider 0〜30%、% 表示) - MktNm を multiselect - S33Nm を multiselect- メイン - 件数 / PER 平均 / 配当利回り平均 のメトリクス - リスク・リターン散布図(全体グレー + 該当強調、Plotly) - 結果テーブル(per 昇順) - 結果 CSV のダウンロードボタン
制約:- streamlit 1.40 系 / pandas 2.2 系 / plotly 5.20 系- 結果が 0 件のときは st.warning → st.stop- @st.cache_data で metrics 読み込みをキャッシュ- ファイル名は screener.pyまとめ
- スライダー × multiselect で、ファンダメンタルズ指標のスクリーニング UI が作れる
- 散布図は「全体グレー + 該当を強調」で全体の中の位置を見せる
- 結果は CSV ダウンロードできる形にして、後段の分析に繋げる
- 0 件のとき・NaN 行の扱いを事前に決めておく
過去のデータでの集計は将来の業績・株価を保証しません。