最大ドローダウン(maximum drawdown、MDD)は、資産曲線が過去の最高値から最も深く落ち込んだ割合を表す指標です。本記事では、累積リターン曲線から MDD を計算し、ドローダウン期間を可視化する手順を Python で整理します。
目次
- 定義
- なぜシャープレシオと一緒に見るのか
- サンプルデータの準備
- ドローダウン系列の計算
- 最大ドローダウンと発生日
- 回復までの日数
- 可視化
- 関数化
- 補助指標: カルマーレシオ
定義
ドローダウン(drawdown)は、ある時点 までの資産曲線の 最高値からの落ち込み率 です。
- : 時点 の資産価値(累積リターンや評価額)
- 値は常に 。0 のときは過去最高値を更新中
最大ドローダウン MDD は、期間内のドローダウンの最小値(最も深い落ち込み)です。
「年間で何 % 下がる可能性があるか」というより、「過去の運用で実際に経験した最悪の落ち込み」を示す指標です。
なぜシャープレシオと一緒に見るのか
シャープレシオは平均と標準偏差で評価しますが、緩やかに損失を続ける戦略 と 短期間に大きく落ちる戦略 を区別しません。MDD はこの「経路」の悪さを直接表現します。
- シャープが同じでも MDD が深い戦略は、心理的・制度的に保有が難しい
- 機関投資家のリスク管理では「許容 MDD」を定めて運用する例が多い
サンプルデータの準備
日次リターンから資産曲線(初期資金 100 万円)を作ります。
import numpy as npimport pandas as pd
rng = np.random.default_rng(seed=21)n_days = 1000
returns = pd.Series( rng.standard_t(df=6, size=n_days) * 0.012 + 0.0003, index=pd.date_range("2022-01-04", periods=n_days, freq="B"), name="ret",)
INITIAL_CAPITAL = 1_000_000equity = INITIAL_CAPITAL * (1 + returns).cumprod()実データでは returns を J-Quants 由来の日次リターンや、戦略のリターン列に置き換えてください。
ドローダウン系列の計算
cummax で過去最高値を取り、現在値との比率を計算します。
running_max = equity.cummax()drawdown = (equity - running_max) / running_maxprint(drawdown.describe())cummax: 累積最大値。最高値を更新するたびに値が更新される- 結果は常に 。0 のときは「過去最高値を更新中」
最大ドローダウンと発生日
MDD と、その発生日(谷)を取り出します。さらに、その直前の山(ピーク)もたどります。
mdd_value = drawdown.min()trough = drawdown.idxmin() # 最も深い谷の日付peak = equity.loc[:trough].idxmax() # 谷より前で資産曲線が最大の日付
print(f"最大ドローダウン: {mdd_value:.4f} ({mdd_value * 100:.2f}%)")print(f"ピーク日: {peak.date()}")print(f"谷日: {trough.date()}")print(f"下落日数: {(trough - peak).days} 日")回復までの日数
谷から「ピーク水準を再び超えた日」までを回復期間と呼びます。回復していない場合は None を返すように書きます。
def days_to_recover(equity: pd.Series, peak_date: pd.Timestamp) -> int | None: """ピーク日以降に、ピーク値を超えるまでの日数を返す。未回復は None。""" peak_value = equity.loc[peak_date] after = equity.loc[peak_date:] recovered = after[after >= peak_value] if len(recovered) <= 1: return None return (recovered.index[1] - peak_date).days
recover_days = days_to_recover(equity, peak)print(f"回復までの日数: {recover_days}")recovered.index[0] はピーク当日(自身)なので、[1] 以降を採用します。
可視化
資産曲線とドローダウンを 2 段で並べます。
import matplotlib.pyplot as plt
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(9, 6), sharex=True)
ax1.plot(equity.index, equity, color="tab:blue", label="equity")ax1.plot(equity.index, equity.cummax(), color="tab:orange", linewidth=0.8, label="running max")ax1.scatter([peak, trough], [equity.loc[peak], equity.loc[trough]], color="red", zorder=3)ax1.set_ylabel("Eq (JPY)")ax1.legend()ax1.grid(alpha=0.3)
ax2.fill_between(drawdown.index, drawdown, 0, color="tab:red", alpha=0.4)ax2.set_ylabel("Drawdown")ax2.set_xlabel("Date")ax2.grid(alpha=0.3)
fig.suptitle(f"Eq & drawdown (MDD = {mdd_value * 100:.2f}%)")plt.tight_layout()plt.savefig("drawdown.png", dpi=120)plt.close(fig)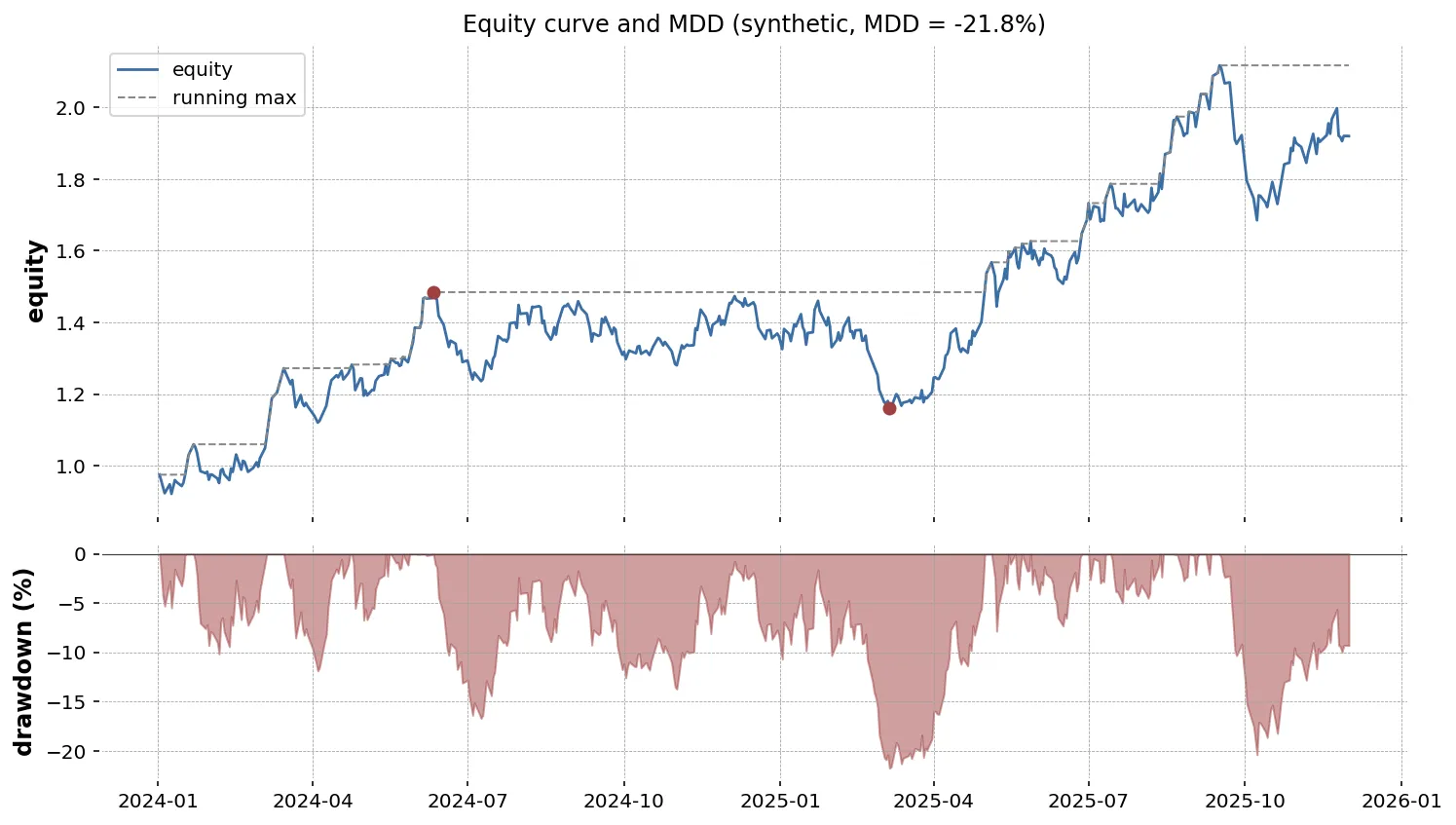
ドローダウンの図(下段)は常に 0 以下なので、塗りつぶしで深さが直感的に伝わります。
関数化
戦略比較で使い回せるように、評価指標としてまとめます。
def drawdown_summary(returns: pd.Series, initial: float = 1.0) -> dict[str, float]: """日次リターン列から MDD・ピーク・谷・下落日数の概要を返す。""" equity = initial * (1 + returns.fillna(0)).cumprod() running_max = equity.cummax() dd = (equity - running_max) / running_max
trough = dd.idxmin() peak = equity.loc[:trough].idxmax()
return { "mdd": float(dd.min()), "peak_date": peak, "trough_date": trough, "drop_days": int((trough - peak).days), }
print(drawdown_summary(returns))補助指標: カルマーレシオ
CAGR(年率複利リターン)を MDD の絶対値で割った カルマーレシオ(Calmar ratio) は、MDD ベースのリスク調整リターンとしてよく使われます。
TRADING_DAYS = 252years = len(returns) / TRADING_DAYScagr = (equity.iloc[-1] / INITIAL_CAPITAL) ** (1 / years) - 1calmar = cagr / abs(mdd_value) if mdd_value != 0 else float("nan")print(f"CAGR: {cagr:.4f}")print(f"Calmar: {calmar:.4f}")シャープレシオが「平均と標準偏差」、カルマーレシオが「平均と最悪の落ち込み」と覚えると整理しやすくなります。
注意点
- MDD は最悪の経験値: 過去のサンプルに依存し、将来の最悪値を保証しません
- 期間の長さで変わる: 長期間ほど MDD は深くなりやすいので、期間を揃えて比較します
- 配当・分割の調整: 調整なしの株価で計算すると、分割の日に偽のドローダウンが入ります(調整済み終値の利用が前提)
- 複利と単利: 累積リターンの計算で
(1 + r).cumprod()を使うのが慣例です。対数リターンの場合はnp.exp(log_ret.cumsum())でも同等
生成AI へのプロンプト例
複数戦略を 1 表で比較したいときの例です。
入力 DataFrame に次の列があります:- date (datetime64)- strategy (str)- ret (float, 日次リターン、コスト控除後)
各 strategy について、次の列を持つ DataFrame を返す関数risk_table(df, initial=1.0) を書いてください。
戻り値の列:- strategy- cum_return: 累積リターン- cagr: 年率複利リターン (252 日換算)- mdd: 最大ドローダウン (負の値)- peak_date / trough_date: MDD のピーク日と谷日- calmar: cagr / |mdd|
要件:- pandas 2.2 / numpy 系- リターンの NaN は 0 で埋める- mdd が 0 のときは calmar を NaN- docstring を日本語で書くまとめ
- ドローダウンは「過去の最高値からの落ち込み率」、MDD はその最小値
equity.cummax()で資産曲線の最高値、差を取って割ればドローダウン系列- ピーク日・谷日・回復日を一緒に出すと戦略比較が立体的になる
- カルマーレシオは MDD ベースのリスク調整リターン
- 期間と調整済み終値の前提を揃えて比較する