ファクター(factor、要因)とは、銘柄を「ある特性」で並べ替えるとリターンに差が出る、という経験的な観察に基づくスコアです。本記事では、代表的なファクターであるバリュー・モメンタムの考え方を整理し、1 ファクターでの ロング・ショート(long-short) 簡易シミュレーションを Python で実装します。
目次
- ファクターとは
- ロング・ショートポートフォリオの考え方
- サンプルデータの準備
- モメンタムスコアの計算
- クインタイル分け
- ロング・ショートリターン
- 累積損益と評価
- クインタイル別リターン
- 可視化
- 取引コストの考慮
- バリューファクターの場合
ファクターとは
ファクターは「銘柄をスコア化し、スコアに沿って並べたグループのリターン差」を観察するアプローチです。代表例は次の通りです。
| ファクター | スコアの定義例 | 経験則 |
|---|---|---|
| バリュー(value) | PER の逆数、PBR の逆数、配当利回り | 割安銘柄が長期に上回る傾向 |
| モメンタム(momentum) | 過去 12 か月リターン(直近 1 か月除く) | 直近の勝者が短期で続伸する傾向 |
| サイズ(size) | 時価総額の小ささ | 小型株が長期に上回る傾向 |
| クオリティ(quality) | 自己資本利益率、利益安定性 | 質の高い銘柄が安定して上回る傾向 |
| ローボラ(low vol) | 過去ボラティリティの低さ | リスク調整後で上回る傾向 |
これらは「100% 機能する法則」ではなく、長期に観察される 平均的な傾向 です。期間や市場、コスト前提によっては機能しない時期もあります。
ロング・ショートポートフォリオの考え方
ロング・ショートとは、スコアの高い側を買い(long)、低い側を売る(short)構造のポートフォリオです。市場全体の動き(beta)を相殺し、ファクターのスコア差そのものを損益として取り出すのが狙いです。
| グループ | 構成 | 重み |
|---|---|---|
| Q5(High) | スコア上位 20% | +1 / N |
| Q1(Low) | スコア下位 20% | -1 / N |
| 戦略リターン | Q5 平均リターン − Q1 平均リターン | 等加重 |
5 分位(quintile)に分けるのが慣例ですが、3 分位や 10 分位を使う文献もあります。
サンプルデータの準備
100 銘柄・約 5 年の日次リターンと、各銘柄に 12 か月モメンタムスコアを与えます。実データを使う場合、ロング形式 DataFrame からモメンタムや PER の逆数を計算してください。
import numpy as npimport pandas as pd
rng = np.random.default_rng(seed=51)n_days = 1250n_tickers = 100tickers = [f"T{i:03d}" for i in range(n_tickers)]
# 各銘柄に異なる平均と相関を仮定したリターンmu = rng.normal(0.0002, 0.0004, size=n_tickers)sigma = rng.uniform(0.012, 0.025, size=n_tickers)
returns = pd.DataFrame( rng.normal(mu, sigma, size=(n_days, n_tickers)), index=pd.date_range("2021-01-04", periods=n_days, freq="B"), columns=tickers,)print(returns.iloc[:3, :5].round(5))モメンタムスコアの計算
「過去 12 か月リターン、ただし直近 1 か月を除く」が標準的な定義です。直近 1 か月を除くのは、短期の反発(リバーサル)が逆向きに効くためです。
LOOKBACK = 252 # 約 12 か月SKIP = 21 # 約 1 か月
# 過去 252 日の累積リターンから、直近 21 日の累積リターンを引いた近似log_ret = np.log1p(returns)mom_long = log_ret.rolling(LOOKBACK).sum()mom_short = log_ret.rolling(SKIP).sum()
# 当日の close 情報を使ってしまわないよう shift(1)score = (mom_long - mom_short).shift(1)print(score.iloc[-3:, :5].round(4))shift(1) を入れることで、「当日の終値情報を使ってその日のうちに約定する」誤りを防ぎます(先読みバイアス防止)。
クインタイル分け
各日付ごとにスコアの 5 分位を計算し、Q1(下位 20%)と Q5(上位 20%)のグループを作ります。
def quintile_groups(score_row: pd.Series) -> pd.Series: """1 日分のスコアから、5 分位ラベル (1〜5) を返す。""" return pd.qcut(score_row.dropna(), q=5, labels=False, duplicates="drop") + 1
groups = score.apply(quintile_groups, axis=1)print(groups.iloc[-1].value_counts())pd.qcut は欠損を扱えないため、dropna で除いてから分位ラベルを付けます。labels=False で 0〜4 が出るので、+1 で 1〜5 に揃えています。
ロング・ショートリターン
各日付のリターンを、Q5 と Q1 の 次営業日のリターン に対して等加重平均で取ります。スコアが当日終値の情報を含むため、リターンは翌日(スコアを shift(1) 済みなので、ここでは同日のリターン)を使う形になります。
def daily_ls_return(date: pd.Timestamp) -> float: g_today = groups.loc[date] r_today = returns.loc[date] long_ret = r_today[g_today == 5].mean() short_ret = r_today[g_today == 1].mean() if pd.isna(long_ret) or pd.isna(short_ret): return np.nan return long_ret - short_ret
valid_dates = groups.dropna(how="all").indexls_ret = pd.Series([daily_ls_return(d) for d in valid_dates], index=valid_dates, name="ls_ret")print(ls_ret.tail())累積損益と評価
TRADING_DAYS = 252
ls_clean = ls_ret.dropna()equity = (1 + ls_clean).cumprod()n = len(ls_clean)years = n / TRADING_DAYS
cum_ret = equity.iloc[-1] - 1cagr = equity.iloc[-1] ** (1 / years) - 1 if years > 0 else float("nan")sharpe = (ls_clean.mean() / ls_clean.std(ddof=0)) * np.sqrt(TRADING_DAYS) if ls_clean.std(ddof=0) > 0 else float("nan")mdd = ((equity - equity.cummax()) / equity.cummax()).min()
print(f"累積リターン: {cum_ret:.4f}")print(f"CAGR: {cagr:.4f}")print(f"年率シャープ: {sharpe:.4f}")print(f"最大DD: {mdd:.4f}")評価指標の構成は#10-6「バックテストの最小実装」 と同じ 3 点セットです(CAGR / シャープ / MDD)。
クインタイル別リターン
5 分位それぞれの平均リターンを比較すると、ファクターの効きが分位順に並んでいるかが見えます。きれいに単調(Q1 < Q2 < … < Q5)であれば、ファクターが機能していると解釈できます。
quintile_returns = pd.DataFrame( {q: returns.where(groups == q).mean(axis=1) for q in range(1, 6)},)print(quintile_returns.mean() * TRADING_DAYS) # 年率に換算可視化
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(9, 4))for q in range(1, 6): eq_q = (1 + quintile_returns[q].fillna(0)).cumprod() ax.plot(eq_q.index, eq_q, label=f"Q{q}")ax.set_title("Cumulative return by quintile")ax.set_ylabel("Eq (start = 1.0)")ax.set_xlabel("Date")ax.grid(alpha=0.3)ax.legend()plt.tight_layout()plt.savefig("factor_quintiles.png", dpi=120)plt.close(fig)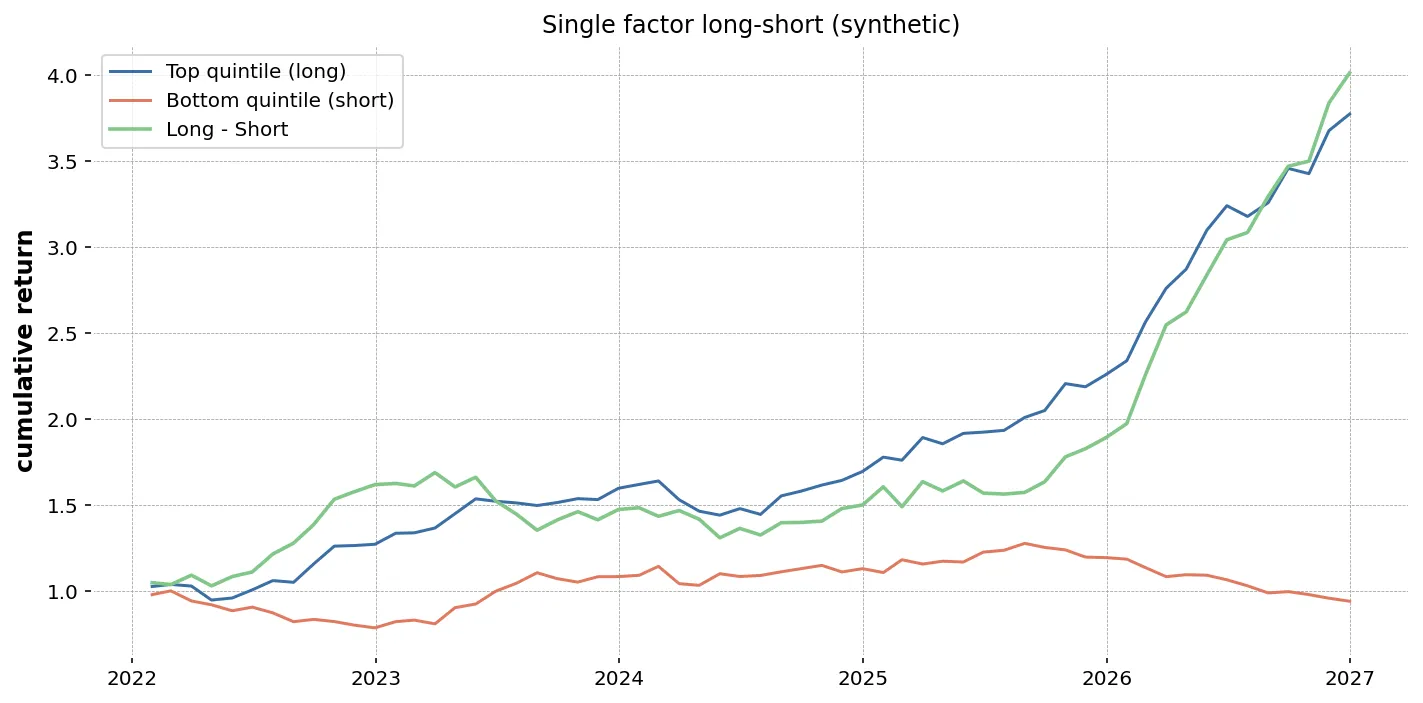
Q5 が最上、Q1 が最下に並んでいれば、モメンタムスコアでリターンの順序が分けられたことになります。
取引コストの考慮
実運用では、銘柄入れ替えごとにコストが発生します。日次でグループが変わると往復コストが嵩むため、月次リバランス(月初だけグループを更新)が現実的です。
# 月初日だけグループを更新する近似month_starts = groups.resample("MS").first().indexgroups_monthly = groups.reindex(groups.index)groups_monthly = groups_monthly.where(groups_monthly.index.isin(month_starts)).ffill()加えて、各リバランス日に「ロング・ショート両側を入れ替えた銘柄数」に応じてコストを差し引きます。コストの組み込みは#11-3「移動平均クロス戦略を 5 銘柄でバックテスト」 / #10-6「バックテストの最小実装」 を参考に、「ポジション変化量 × 片道コスト」で素直に減算する方式が分かりやすい実装です。
バリューファクターの場合
PER の逆数(EP = 1 / PER)や PBR の逆数(BP = 1 / PBR)をスコアにする場合、流れは同じです。違いはスコアの計算式と更新頻度(財務データは四半期更新)だけです。
# 仮想: ep = pd.DataFrame(index=date, columns=ticker) で 1/PER のスコア# score = ep.shift(1) # 同様に shift(1) で先読み防止財務データは「公表日」と「対象期間の終了日」が異なる点に注意します。スコア更新は 公表日以降 にしないと、実際には知り得なかった数字を使う形になります。
注意点
- 取引コストとリバランス頻度: 日次リバランスは現実離れ。月次以上が実運用の出発点
- 空売り規制・コスト: ショート側は借株コスト・規制があり、現実のコストは買いより高くなりがち
- ファクターの相関: モメンタムとサイズなど、複数ファクターは相関を持つ。重ねるときは寄与の重複を意識
- ファクターの周期性: 効くときと効かないときの時期がある。長期で平均化して評価
- 生存者バイアス: 上場廃止銘柄を含めずに検証すると、スコア下位グループの損失が過小になる(#10-7「バックテストの落とし穴(俯瞰)」)
本記事のコードは学習目的のシミュレーションで、実発注 API は呼びません。
生成AI へのプロンプト例
複数ファクターを 1 つの関数で評価したい場合の例です。
入力:- returns: pd.DataFrame, index=date (datetime64), columns=ticker, 値=日次リターン- scores: pd.DataFrame, index=date (datetime64), columns=ticker, 値=ファクタースコア(高いほど良い)
次の関数 long_short_backtest(returns, scores, n_quantiles=5, rebalance="M") を書いてください。
仕様:- scores を shift(1) して先読みを防ぐ- 各リバランス日(月初など)に n_quantiles 分位でグループ化- 戦略リターン: 上位グループの等加重リターン − 下位グループの等加重リターン- 戻り値: pd.Series(index=date, value=日次戦略リターン)
要件:- pandas 2.2 系- 欠損を持つ日は dropna でスキップ- docstring を日本語で書くまとめ
- ファクターは「銘柄をスコアで並べると平均リターンに差が出る」観察
- バリュー・モメンタム・サイズ・クオリティ・ローボラが代表的
- ロング・ショートで市場全体の動きを相殺し、スコア差そのものを取り出す
- スコアは必ず
shift(1)で先読みを防ぐ - リバランス頻度・取引コスト・生存者バイアスが結果に大きく効く