リターンの「平均」「標準偏差」「最大」「最小」だけを見ても、リスクの実態は分かりません。本記事では 分布の形 に注目し、ヒストグラムと QQ プロットで「正規分布からの外れ方」を可視化する手順を整理します。
目次
- なぜ「分布」を見るのか
- サンプルデータの準備
- 基本統計量を出す
- ヒストグラム
- QQ プロット
- 正規性の検定(参考)
- 実務での使い方
なぜ「分布」を見るのか
統計やバックテストの多くは、暗黙のうちに リターンが正規分布する と仮定します。しかし実際の株式リターンは、
- 裾(テール)が厚い: 大きな上下が、正規分布の予測より頻繁に起きる
- 左右非対称(歪み): 暴落のほうが急激で、上昇は緩やかなことが多い
- クラスタリング: 大きく動く日が固まって発生する(ボラティリティが時間で変わる)
といった性質を持ちます。これらに気づかずにリスクを評価すると、実際より安全に見える モデルを作ってしまいます。分布を見ることはリスク評価の前提です。
サンプルデータの準備
ランダムウォークではなく、現実に近い「裾の厚い」乱数で日次リターンを生成します。
import numpy as npimport pandas as pd
rng = np.random.default_rng(seed=42)n_days = 1000
# 自由度 5 の t 分布(裾が厚い)からリターンを生成returns = pd.Series( rng.standard_t(df=5, size=n_days) * 0.012, index=pd.date_range("2022-01-03", periods=n_days, freq="B"), name="log_return",)print(returns.head())実データを使う場合は、J-Quants の日次株価から対数リターンを計算したものを returns の代わりに渡します(#5-9「リターンの種類 — 単純リターンと対数リターン」 / #6-5「日次株価四本値を取得する (/equities/bars/daily)」)。
基本統計量を出す
最初に大づかみな統計量を確認します。
import scipy.stats as stats
print(returns.describe())print(f"歪度 (skew): {stats.skew(returns):.3f}")print(f"尖度 (kurtosis): {stats.kurtosis(returns, fisher=True):.3f}")- 歪度(skewness): 0 が左右対称。負だと「下側の裾が長い」(暴落寄り)
- 尖度(kurtosis): 正規分布が 0(Fisher 流)。正だと「裾が厚い」
株式リターンは経験的に 歪度が負、尖度が正 になりやすい、という見方があります。
ヒストグラム
頻度分布を直接見る方法です。正規分布のフィッティング曲線も重ねると、ズレが視覚的に分かります。
import matplotlib.pyplot as pltimport numpy as np
mu, sigma = returns.mean(), returns.std(ddof=0)xs = np.linspace(returns.min(), returns.max(), 200)pdf = (1 / (sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((xs - mu) / sigma) ** 2)
fig, ax = plt.subplots(figsize=(8, 5))ax.hist(returns, bins=60, density=True, alpha=0.6, color="tab:blue", label="empirical")ax.plot(xs, pdf, color="tab:red", linewidth=2, label="normal fit")ax.axvline(mu, color="black", linestyle="--", linewidth=0.8)ax.set_xlabel("daily log-return")ax.set_ylabel("density")ax.set_title("Distribution of daily returns")ax.legend()ax.grid(alpha=0.3)plt.tight_layout()plt.savefig("return_hist.png", dpi=120)plt.close(fig)ヒストグラムが正規分布カーブの中心では低く、両端では高い場合、それが 裾の厚さ の現れです。
QQ プロット
「経験分布の各分位点が、正規分布の各分位点とどれだけ一致するか」を散布図で見るのが QQ プロット(quantile-quantile plot)です。
fig, ax = plt.subplots(figsize=(6, 6))stats.probplot(returns, dist="norm", plot=ax)ax.set_title("Normal QQ-plot of daily returns")ax.grid(alpha=0.3)plt.tight_layout()plt.savefig("return_qq.png", dpi=120)plt.close(fig)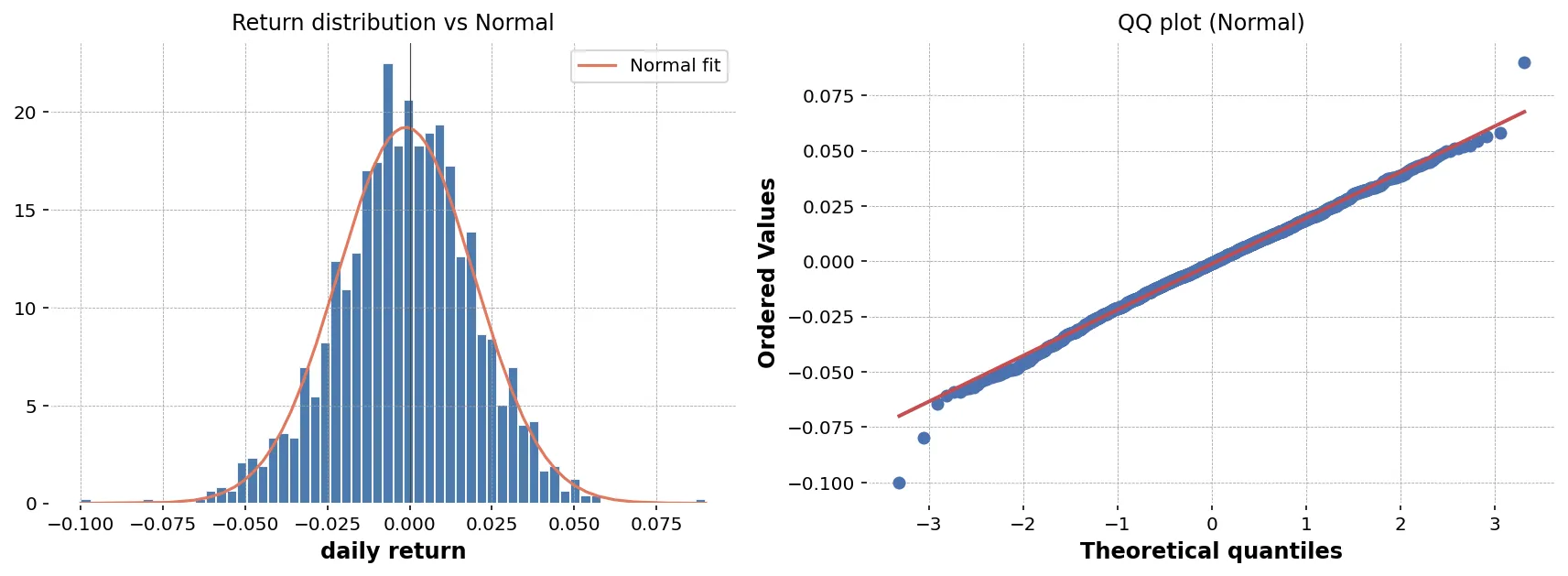
理論線(直線)からデータ点(散布点)が
- 両端で上下に大きく外れる → 裾が厚い
- 片側だけ外れる → 歪んでいる
- 中央付近だけ少し外れる → 軽度のズレ。実用上は無視できることも
経験的に株式リターンは、両端で直線から大きく外れる傾向があります。
正規性の検定(参考)
数値で判定したい場合、Shapiro-Wilk や Jarque-Bera 検定が使えます。ただし、サンプルサイズが大きいと「ほぼ確実に有意」になるため、検定結果より 絵で見る ほうが実用的です。
stat, p = stats.jarque_bera(returns)print(f"Jarque-Bera 統計量: {stat:.2f}, p-value: {p:.4g}")p-value < 0.05 であれば「正規分布ではない」と判定されますが、株式リターンの場合はサンプルが多いほどほぼ常に有意になります。
実務での使い方
分布の確認は、次のような場面で役立ちます。
- バックテストの妥当性検証: 大きな下落シナリオを、サンプルが十分カバーしているか
- リスク指標の解釈: 標準偏差だけでは捉えきれない「外れた日」を意識する
- モデル選定: 正規分布前提のモデル(平均-分散ポートフォリオ最適化など)を使う前のチェック
- 異常検知: 過去の分布から大きく外れた日を「特別なイベント」として扱う
生成AI へのプロンプト例
複数銘柄について分布チェックをバッチ化したい場合の例です。
入力 DataFrame に次の列があります:- date (datetime64)- ticker (str)- log_return (float)
各 ticker について、次を計算する関数 distribution_summary(df) を書いてください。
戻り値: 1 ticker = 1 行の DataFrame列: ticker, n, mean, std, skew, kurtosis, jb_pvalue, q01, q99
要件:- pandas 2.2 / scipy 1.13 系- skew は scipy.stats.skew, kurtosis は fisher=True- q01 / q99 はパーセンタイル(0.01 / 0.99)- ticker ごとに NaN を除いて計算- docstring を日本語で書くまとめ
- 株式リターンは 正規分布ではない(裾が厚い・歪み・クラスタリング)
- 平均と標準偏差だけではリスクを過小評価する
- ヒストグラム + 正規分布フィットで全体像を把握する
- QQ プロットで両端のズレを見る
- 検定はサンプル数が多いとほぼ常に有意。絵で見る ことを優先