ある変数からもう 1 つの変数を直線で説明する手法が、単回帰分析(simple linear regression)です。本記事では、最小二乗法の式と直感、Python での実装、結果の読み方を整理します。
目次
- 単回帰のモデル
- 最小二乗法
- Python で計算する
- 決定係数
- statsmodels で詳細を見る
- 残差の確認
単回帰のモデル
説明変数 と目的変数 を、次の直線で関係づけるモデルです。
- : 切片(intercept)
- : 傾き(slope)
- : 誤差(noise)
株式の文脈では「市場リターン()に対する個別銘柄リターン()」のような関係を、傾き(、ベータ)として表す使い方が代表例です。
最小二乗法
各点のずれの 2 乗和(残差平方和、residual sum of squares)を最小にする を選ぶ手法が、最小二乗法(OLS、Ordinary Least Squares)です。
解は閉じた形で求まります。
傾きが共分散と分散の比で書けるのが、相関係数(#5-5「相関係数と共分散」)とつながる点です。
Python で計算する
NumPy の polyfit で 1 次の直線を当てはめる例です。
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt
rng = np.random.default_rng(0)n = 250
# 市場リターン(説明変数)market = rng.normal(loc=0.0, scale=0.012, size=n)
# 個別銘柄リターン: y = 0.0002 + 1.2 * market + ノイズstock = 0.0002 + 1.2 * market + rng.normal(0.0, 0.008, size=n)
slope, intercept = np.polyfit(market, stock, deg=1)print(f"傾き(β1) : {slope:.4f}")print(f"切片(β0): {intercept:.6f}")
# 予測線xs = np.linspace(market.min(), market.max(), 100)ys = intercept + slope * xs
fig, ax = plt.subplots(figsize=(6, 5))ax.scatter(market, stock, alpha=0.5, s=10)ax.plot(xs, ys, color="red")ax.set_xlabel("market return")ax.set_ylabel("stock return")ax.set_title("Simple linear regression")plt.tight_layout()plt.show()傾きが 1.2 付近に推定されていれば、市場が 1% 動いたとき個別銘柄が約 1.2% 動く、という関係を捉えています。
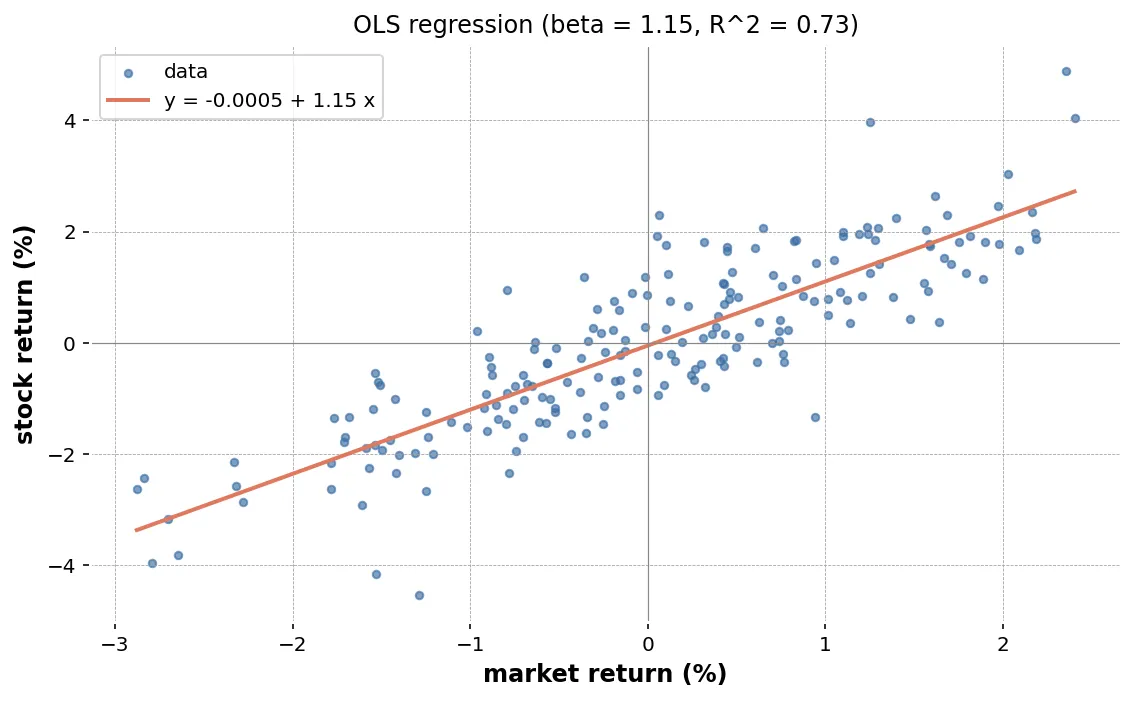
決定係数
回帰の当てはまりの良さを表すのが、決定係数 です。
- : すべての点が回帰直線上にある
- : 平均で予測するのと同じ程度の精度
単回帰の場合、 は相関係数の 2 乗に等しくなります。
correlation = np.corrcoef(market, stock)[0, 1]predicted = intercept + slope * marketss_res = np.sum((stock - predicted) ** 2)ss_tot = np.sum((stock - stock.mean()) ** 2)r_squared = 1 - ss_res / ss_tot
print(f"相関係数: {correlation:.4f}")print(f"R^2 : {r_squared:.4f}")statsmodels で詳細を見る
p 値や信頼区間まで欲しい場合は statsmodels が手軽です。
import statsmodels.api as sm
X = sm.add_constant(market) # 切片用の定数列を加えるmodel = sm.OLS(stock, X).fit()print(model.summary())主な読みどころは次のとおりです。
coef: 回帰係数の推定値std err: 標準誤差t/P>|t|: 各係数の t 値と p 値(0 と異なるかの検定)R-squared: 決定係数
残差の確認
回帰モデルの妥当性は、残差(実測値と予測値の差)の散らばりで確認します。
residuals = stock - predicted
fig, ax = plt.subplots(figsize=(6, 4))ax.scatter(predicted, residuals, alpha=0.5, s=10)ax.axhline(0, color="gray")ax.set_xlabel("predicted")ax.set_ylabel("residual")ax.set_title("Residual plot")plt.tight_layout()plt.show()理想的には、残差は予測値によらず 0 を中心に均等に散らばります。残差にパターン(扇型・曲線)が見えたら、線形モデルの仮定が崩れているサインです。
注意点
- 単回帰は「1 つの変数だけで説明する」モデル。本来は複数要因の影響を受けるなら重回帰(#5-8「重回帰分析の入門」)
- 外れ値に弱い(最小二乗法は 2 乗で重みづけるため、外れ値の影響が大きく出る)
- 回帰係数の有意性検定は、残差が独立で分散一定・正規という前提に立つ
- 過去の関係が将来も続く保証はない
生成AI へのプロンプト例
ベータ計算を関数化する例です。
銘柄リターン(pandas Series)と市場リターン(pandas Series)を受け取り、単回帰でベータと R^2 を計算する関数 estimate_beta(stock_returns, market_returns)を書いてください。
戻り値: dict- alpha(切片)、beta(傾き)、r_squared- n(観測数)、residual_std
要件:- 入力に欠損があれば inner join で揃える- pandas 2.2 系の API を使う- numpy の polyfit ではなく statsmodels の OLS を使う- docstring を日本語で書くまとめ
- 単回帰は 1 つの説明変数で目的変数を直線で説明するモデル
- 最小二乗法の解は共分散と分散の比で書ける
- 決定係数 は当てはまりの良さの指標
- 残差プロットで仮定の妥当性を確認